If you’ve been working in SEO for some times already, you must be familiar with web migrations. They often come with their doses of fun and unexpected complications, but they are part of what we do for a living.
If handled poorly, a web migration can have a tremendous effect on online visibility and traffic. Which is obviously what you don’t desire to live through. That being said, a poorly handled migration is, unfortunately, one of the main reasons a business owner will start to take SEO seriously. When I was working agency-side, some of our clients started to work with us after a horrendous experience.
In such a situation, your number one priority when you onboard the client is to understand why the migration is having such an impact on traffic generation and how to fix it quickly. Often, redirects have been implemented poorly, and you need to start reviewing them. A very time-consuming, that can take, literally, days depending on the size of the project. This task is often handled to junior team members (I’ve been there) whose only purpose during days is to fill in an Excel file.
There are situations where it is the only situation because you cannot find any pattern to speed up your work. Fine, but often there are indeed better ways to proceed.
Let me walk through two quick and cost-efficient approaches you can take to save days of manual work to your team or yourself.
The context
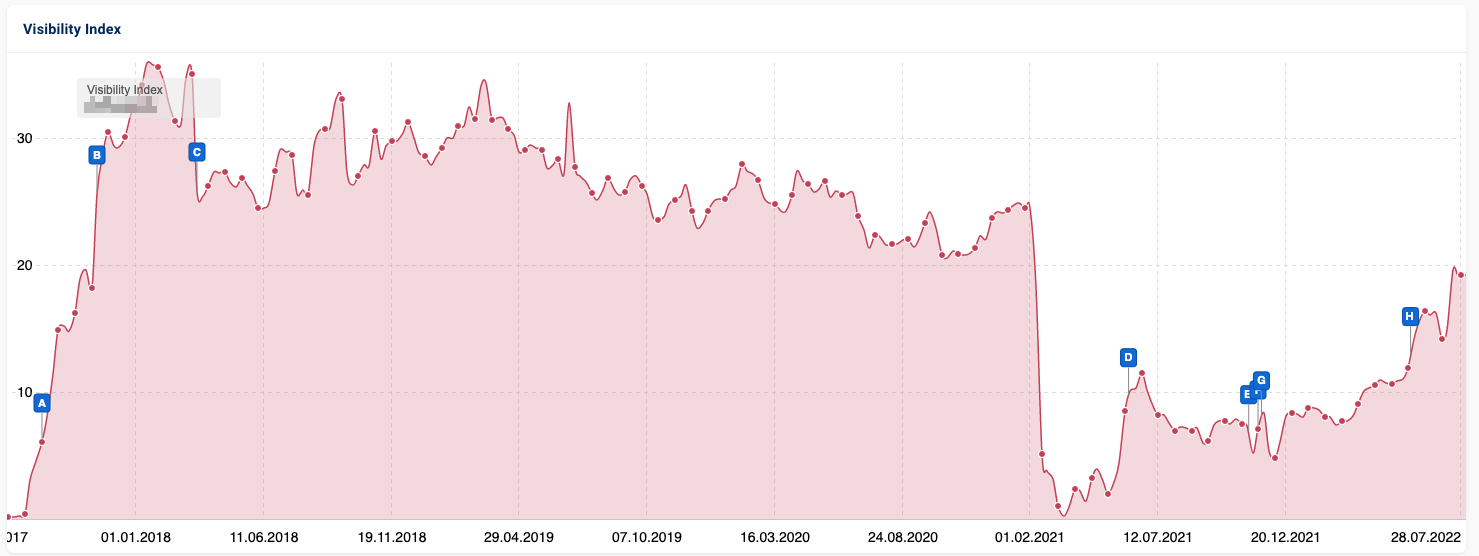
To provide a real context to the article I’m writing, we’ll use the migration that happened some months ago for the French railway company. They decided to move from https://oui.sncf/ to https://www.sncf-connect.com/.
The migration was actually handled correctly from an SEO perspective, but let’s assume that it wasn’t and that the company comes to us to try to fix it. They literally have thousands of URLs, so mapping them manually is not an option.
If you look at the position history, you’ll realize that the path (the URL stripped from the domain name) is actually the same, so we could handle this case with a simple redirect rule. But let’s assume – again, I know – that it’s not the case and that we have to find the equivalent, at scale.
Option 1: use semantic proximity
A web migration often comes with some URL changes (which is why you need redirects), but you frequently keep a similar structure. You may add some new words, remove some numbers, but there is a common ground.
This option leverages this and try to find the closest equivalent between our old & new structures, by looking at the URL only. Why don’t we look at content?
- Old content may not be available anymore
- Crawling a website takes time and if we can skip this step, we’ll be able to help our client faster
Now, how the heck are we going to do it?
Fuzzy matching
If you don’t know what fuzzy matching is, you can read this amazing piece by Lazarina Stoy, who explains everything.
As a summary:
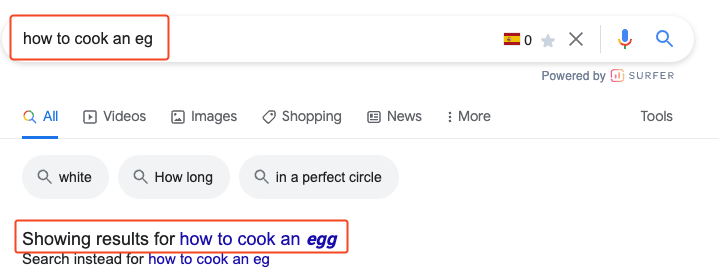
- Fuzzy matching allows us to match similar strings. This is what Google uses to correct spelling mistakes, by the way:
- There are several algorithms available but in our case, we’d use the Levenshtein distance (match words based on number of edits necessary to get from one word to the other) or TF-IDF which looks at how often a set of strings are repeated.
I often use directly Polyfuzz (python library) when I need to use fuzzy matching because it’s effortless to set up. Do not worry if you don’t need either Python or this library, I’ll explain everything and even provide a template.
Our logic
The logic we’ll code is actually pretty simple:
- We’ll first retrieve the two URLs lists we want to match (the old and the new one)
- Run the fuzzy matching between them to define our redirects
- Compare the output of our approach with the actual redirections the SNCF has in place to calculate the success rate
We’ll try to match around 3,000 old URLs to a potential list of around 30,000. I’ve intentionally used a smaller number for the old URLs because the second option (that we’ll see in the next section) is not free, and I didn’t want to spend a lot of money on this explanation.
The code
You can find the code and output here. Even if you don’t understand Python, you’ll see that it’s pretty straightforward.
We first the libraries we need for the script: pandas and polyfuzz.
#load libraries
import pandas as pd
!pip install polyfuzz
from polyfuzz import PolyFuzzWe then load our URLs lists (stored in an Excel file) in pandas DataFrames (which is an equivalent of a table in Python):
#load urls lists
old = pd.read_excel('/content/drive/MyDrive/Website/Content/data_for_posts/redirects_at_scale.xlsx', sheet_name='old')
new = pd.read_excel('/content/drive/MyDrive/Website/Content/data_for_posts/redirects_at_scale.xlsx', sheet_name='new')We continue by converting our pandas DataFrames to regular Python lists (otherwise polyfuzz won’t work) and we launch the fuzzy matching.
#convert to Python list (required by Polyfuzz)
old = old['URL'].tolist()
new = new['URL'].tolist()
#launch fuzzy matching
model = PolyFuzz("TF-IDF")
model.match(old, new)
#load results
result = model.get_matches()The output: our redirect mapping. The output is almost perfect (only 1.3% error our of almost 3,000 URLs) but please note that we are in an ideal situation here, where the old & new structure are very alike.
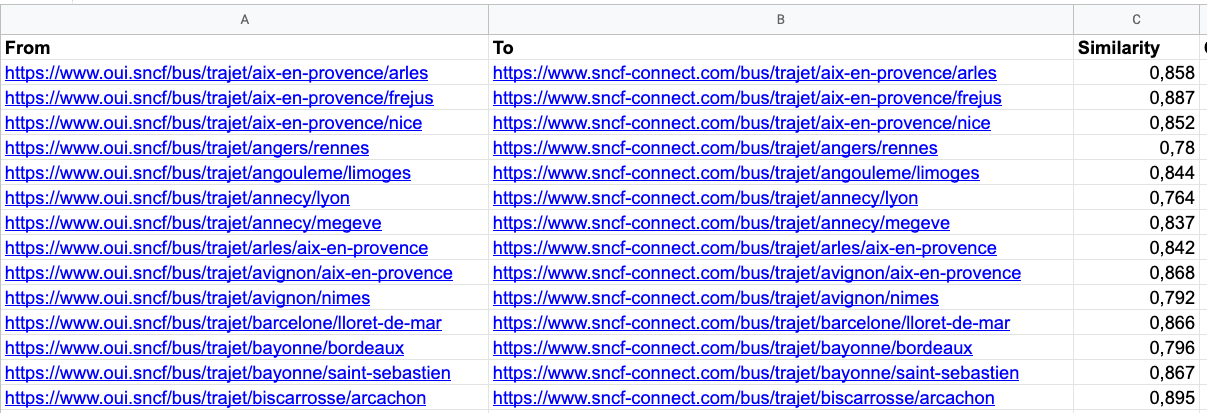
But still, this approach would save you a ton of time and would only require a manual check before its implementation. And you can generate it in less than 2 minutes.
Option 2: hey, Google! Do the work for me!
The first approach is my favorite, but its output depends heavily on how close your URLs structures are. Likely, but not always the case.
The second option is more robust, but only works if the new content is indexed by Google, which means that you’ve been contacted only some days after the migration took place (and it may be too late). Also, it’s not free, although it’s not expansive either.
Our logic
Again, the logic is simple:
- We’ll first, using first or third-part data, extract the keyword that was generating the most traffic per URL
- We’ll then, using the site: operator, get the most relevant result, according to Google, for this query
For instance, https://www.theguardian.com/football/world-cup-2022 is the most relevant URL for the keyword “world cup” for The Guardian.
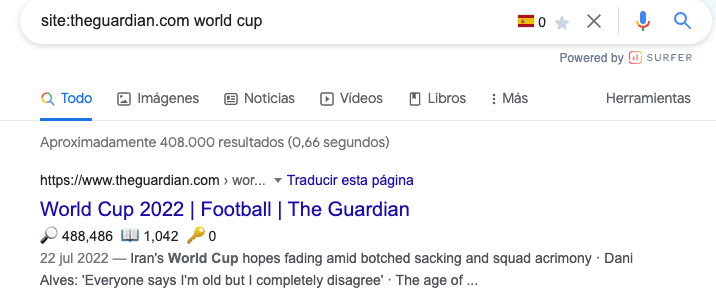
To retrieve data at scale, we’ll use ValueSERP, a great SERP API.
The code
You can find the full code here. This one is more complex than the previous one, and I’ll try to explain it fully.
The first part, as always, is intended as loading the libraries we’ll need for our script: pandas, requests and json. We also add a variable including our API key from ValueSERP. It can be found at the top of your dashboard.
#load libraries
import pandas as pd
import requests
import json
#valueserp key
api_key = ‘’We continue by loading the data from Semrush from our old website. In my example, I use third-part data, but if you can, I strongly advise using data from GSC. The logic being to end up with the most important keyword (in terms of traffic) by URL.
#load file containing keywords
kw = (
pd
.read_csv('/content/drive/MyDrive/Website/Content/data_for_posts/oui.sncf_keywords.csv')
#keep only best kw by traffic
.sort_values(by='Traffic', ascending=False)
.drop_duplicates('URL', keep='first')
#add column with keyword to use in Google
.assign(Keyword_Google = lambda df:'site:sncf-connect.com '+df.Keyword)
)
#remove useless columns
kw = kw[['Keyword','URL','Keyword_Google']]At this stage, we have a DataFrame containing the Google query that we’ll use to find the redirect per URL.
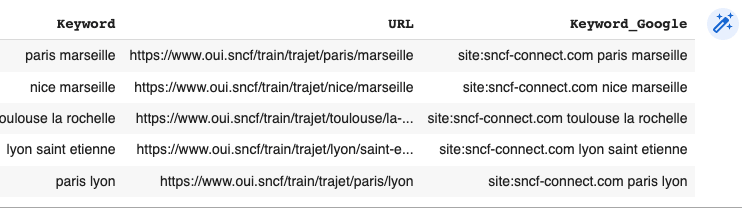
We now can send the information to ValueSERP. I won’t explain in-depth this part because it is based on the documentation, but if you want to use my code, you’d need:
- To create more than one batch, because you cannot have more than 1,000 queries per batch. I decided to limit my extraction at 1,000 to reduce the cost associated to this article
- Update the location, google domain, device …. based on your project
#list of queries to send to ValueSERP
#in this example, I'm just getting the data for 1000 keywords
kws = kw['Keyword_Google'].head(1000).tolist()
location = 'France'
google_domain = 'google.fr'
gl = 'fr'
hl = 'fr'
device = 'desktop'
num = 20
param_list = []
#create a list of parameters for each set
for i in range(0, len(kws)):
param_list.append({
'api_key': api_key,
'q': kws[i],
'location': location,
'google_domain': google_domain,
'gl':gl,
'hl':hl,
'device':device,
'num': str(int(num))
})
#create our batch
body = {
"name":'Demo_SNCF_Connect',
"enabled": True,
"schedule_type": "manual",
"priority": "normal",
"searches_type":"web"
}
#create batch
api_result = requests.post(f'https://api.valueserp.com/batches?api_key={api_key}', json=body)
api_response = api_result.json()
#get id
batch_id = api_response['batch']['id']
#send data to batch
for i in range(0, len(param_list)):
body = {"searches":[]}
for param in param_list:
body["searches"].append(param)
api_result = requests.put(f'https://api.valueserp.com/batches/{batch_id}?api_key={api_key}', json=body).json()Once this code is executed, you’ll have a batch created in ValueSERP and you can (manually) launch the extraction:
It is usually superfast (<1mn) and once it has finished, you can copy the batch ID to execute the rest of the code, which basically retrieve the information provided by ValueSERP, apply some filtering to get the desired data.
#required parameters
params = {
'api_key': api_key,
'page_size':1000
}
batch_id = ''
#get results for ou batches
results = pd.DataFrame()
#get batch info
api_result = requests.get(f'https://api.valueserp.com/batches/{batch_id}/results/1/csv', params=params)
for url_csv in api_result.json()['result']['download_links']['pages']:
results = results.append(pd.read_csv(url_csv), ignore_index=True)
#get results for ou batches
results = pd.DataFrame()
#get batch info
api_result = requests.get(f'https://api.valueserp.com/batches/3F3A94E1/results/1/csv', params=params)
for url_csv in api_result.json()['result']['download_links']['pages']:
results = results.append(pd.read_csv(url_csv), ignore_index=True)
#keep only top URL
results_filtered = results[results['result.organic_results.position']==1]
#remove unsucessful scrape
results_filtered = results_filtered[results_filtered['success']==True]
#keep only useful columns
results_filtered = results_filtered[['search.q','result.organic_results.link']]
#use more standard names
results_filtered.columns = ['Keyword_Google','Redirect_URL']
results_filtered.head()
We end up with a DataFrame including our query and the best result, according to Google. We can now merge this data to our initial table, like we did when we were using Polyfuzz.

The output is actually worse than our previous solution (8.6% of error) but it is still a quite satisfactory result. Imagine the number of hours saved anyway!
Conclusion
Redirections can be time-consuming, but if you use any of these two options to speed up your work, you can deliver more value to your client in a matter of hours than a full team doing manual work in days. And you can then spend more time on tasks that cannot be automatized!
Work smarter, not harder 😉