
Amazon es el mayor sitio web de comercio electrónico del mundo. Pero cuando se trata de su visibilidad en Google, ¿qué tan grande es?
Hace unas semanas, Amazon decidió recortar sus tarifas de afiliación. Seguramente no fue el mejor momento para muchas empresas pequeñas o personas que se ganan la vida con estos sitios web, pero no es uno de los criterios que Amazon utiliza cuando tiene que tomar una decisión, seamos sinceros.
Antes de nada, un pequeño recordatorio para los que aún no lo conozcan. Citaré la definición que incluí en otro post: Las webs de afiliación son uno de los modelos de negocio más sencillos y extendidos en internet. El proceso consiste en construir un sitio web para posicionarse en palabras clave comerciales (como «las mejores zapatillas para correr»), y enlazar a sitios web de comercio electrónico (como Amazon) en su contenido para obtener una comisión sobre los productos comprados por sus usuarios.
Durante mucho tiempo, Amazon tuvo uno de los programas de afiliación más populares porque sus tarifas eran más altas que las de la mayoría de sus competidores. Entonces, ¿por qué las han reducido tanto?
Un supuesto es que Amazon se encuentra ahora en una situación de monopolio en muchos países cuando se trata de comercio electrónico. Una situación similar que tiene Google en el mercado de los motores de búsqueda. Su visibilidad orgánica es alta en las palabras claves comerciales y muchos sitios web afiliados también están allí: ¿por qué la empresa pagaría un alto porcentaje a los afiliados si los clientes son muy propensos a comprar con ellos de todos modos? Eso es lo que compartió Fran Murillo en este tuit.
Y cuando observamos la visibilidad que tiene Amazon en España y se compara con el competidor más cercano (El Corte Inglés), se puede valorar que la diferencia es impresionante y va creciendo.
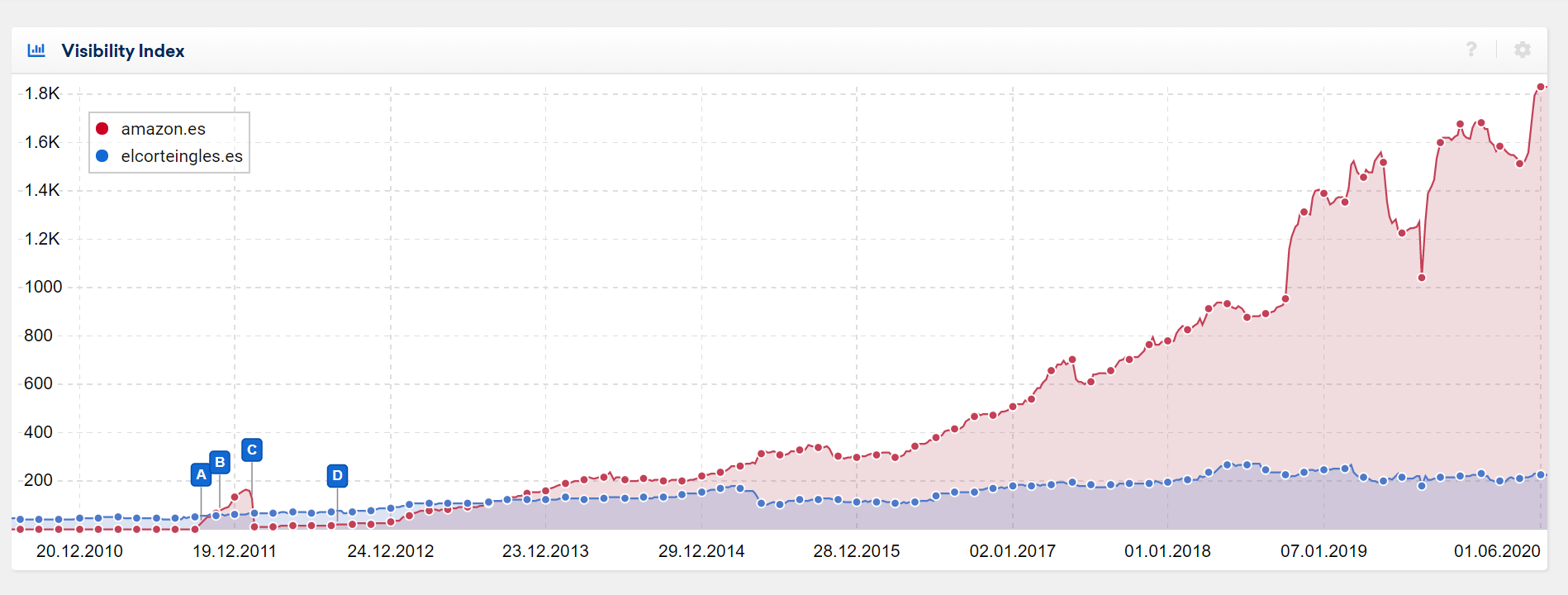
Mismo comentario para las métricas disponibles en Ahrefs:
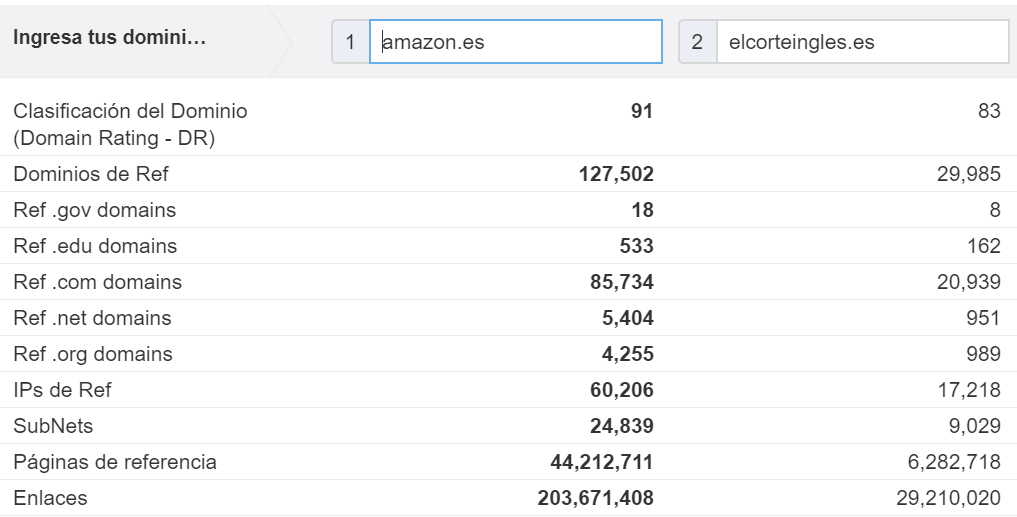
Supongo (como mucha gente) que las comisiones de los afiliados se redujeron porque Amazon no los necesita tanto como antes. De hecho, a menudo está mejor posicionado que ellos y los clientes suelen empezar a buscar un producto en Amazon. Esta es exactamente la razón por la que las palabras clave de marca vinculadas a un producto (como «picadora de carne amazon») se buscan más y más.
Suena bastante lógico, pero ¿qué tal si intentamos validar estas suposiciones basándonos en datos reales? Eso es exactamente lo que he hecho.
Metodología (TL;DR)
Para ver la metodología completa, consulta la sección al final del artículo, donde explico todo más en detalle.
Resumen:
- El estudio se ha realizado únicamente en el mercado español.
- El estudio incluye 14.168 palabras clave transaccionales, con al menos 1.000 búsquedas al mes.
- Extraje los resultados de la primera página de Google (normalmente entre 7 y 10 resultados) para todas estas consultas.
- Después, rastreé todos estos resultados (alrededor de 90.000 URLs individuales) para detectar sitios web con un enlace a Amazon. Si se encontraba un enlace, asumía que este sitio web era un afiliado de Amazon.
El último punto es una suposición fuerte, pero en realidad hay muy pocos sitios web que enlazan a Amazon sin ser un afiliado. El margen de error es bastante bajo aquí.
Problemas comunes con el SEO de Amazon
No es ningún secreto que a Amazon le va muy bien en las consultas transaccionales en Google. Es uno de los mayores E-commerce a nivel mundial y tiene sentido que Google lo incluya en muchas consultas.
Sin embargo, a veces se dan situaciones ridículas que pueden frustrar a otros propietarios de E-commerce. La primera y más frecuente es cuando a Amazon le va muy bien en las consultas con una simple URL de búsqueda interna, como el ejemplo que muestro a continuación.
Y puedo asegurarte que no es un caso aislado. De las 18.479 URLs únicas de Amazon que detecté para todas las consultas que analicé, el 52% eran URLs de resultados de búsqueda.

Nunca he visto tanta importancia para las páginas de resultados de búsqueda y sé perfectamente por qué: las páginas de búsqueda interna suelen ser bloqueadas o con noindex.
Este artículo explica muy bien por qué: para evitar que Google pierda tiempo rastreando páginas inútiles y para ofrecer una buena UX. Pero también explica que hay casos en los que se quiere indexarlas, y Amazon claramente tomó este camino y le funciona bastante bien. Simplemente es más fácil crear a escala enlaces hacia tus páginas de búsqueda que incluirlas en tu arquitectura.
No puedo culpar a Google por posicionarlas tampoco porque, para ser sincero, no hay diferencias prácticas entre una página de categoría y una página de búsqueda para la mayoría de E-commerce. Tienes una lista de productos y un conjunto de filtros que puedes utilizar.
Luego tenemos situaciones en las que hay más de un resultado de Amazon. En mi conjunto de datos, calculé el número de resultados de Amazon por consulta y acabé con el siguiente gráfico de frecuencia, lo que significa que Amazon consigue posicionar más de un resultado en muchos casos.
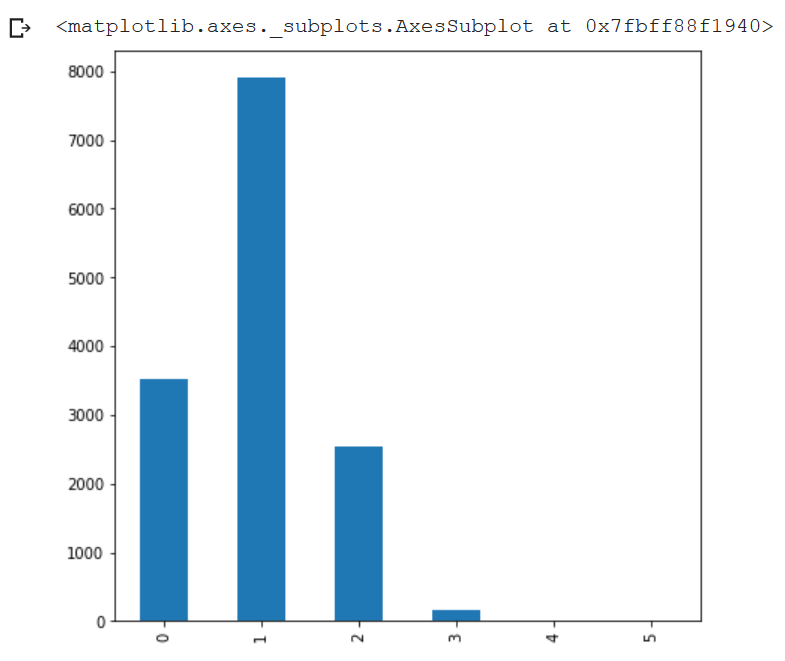
Realmente no sé cómo defender estos casos, principalmente por dos razones:
- Google afirmó que quería incluir más diversidad en sus SERPs y todavía tiene demasiados resultados en los que esto no es así
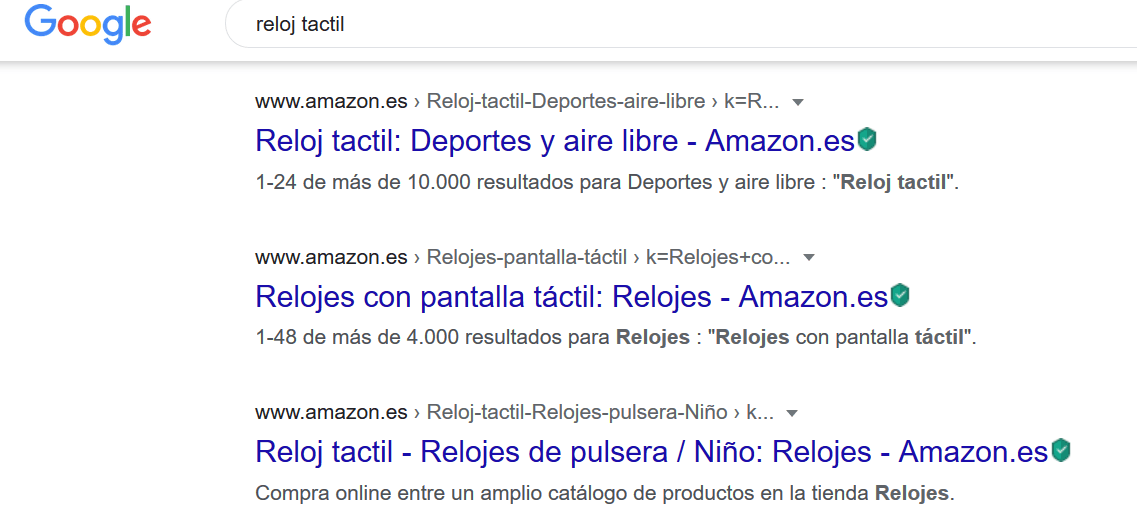
- Se podría argumentar que «sí, pero qué pasa si Google no tiene ningún otro dominio relevante que mostrar». Puedo comprar eso para algunas consultas, pero no para la mayoría, como la consulta «reloj de pantalla táctil», en la que Amazon obtiene los 3 primeros puestos orgánicos:
¿Cuál es la visibilidad (propia) de Amazon?
Basándome en los datos que extraje de las 14.168 consultas, detecté que alrededor del 11% de todos los resultados orgánicos en la primera página eran de Amazon. Tal vez la cifra no sea impresionante a la que esperabas, pero ten en cuenta que el competidor más cercano, El Corte Inglés, sólo está en el 4%.
Este porcentaje se ha obtenido sumando los resultados en los que aparecía amazon.es (10,6%) pero también amazon.com (0,4%), que puede posicionarse en algunos casos.
Además, si extraigo exactamente la misma cifra, pero por posición, te das cuenta de que los resultados de Amazon están muy concentrados en las primeras posiciones. ¿Qué significa esto? que, aunque Amazon tenga el 11% del total de resultados, la cuota de tráfico que obtiene es mayor, porque los 3 primeros resultados suelen obtener entre el 50 y el 80% de los clics (depende del sector y del dispositivo).
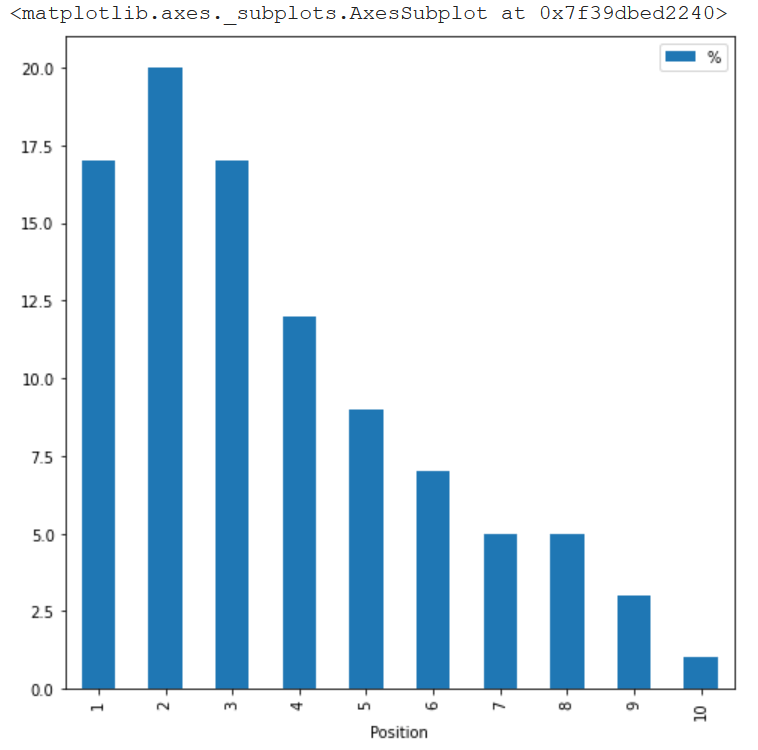
Esto está muy bien, pero lo que realmente queremos averiguar ahora es la visibilidad real que tiene Amazon, con sus propios sitios web pero también con su red de afiliados. ¿Habrá una gran diferencia?
¿Cuál es la visibilidad real de Amazon?
Como explicaba al principio, si una web tenía un enlace a cualquier web de Amazon o amzn.to (muy utilizado para acortar sus URLs), asumía que la web era un afiliado.
Si añadimos los afiliados en el gráfico anterior, acabamos teniendo no un 11% sino un 16% del total de los resultados orgánicos siendo de Amazon o afiliados de Amazon.
En cuanto al reparto, los afiliados suelen estar situados más abajo que Amazon en Google:
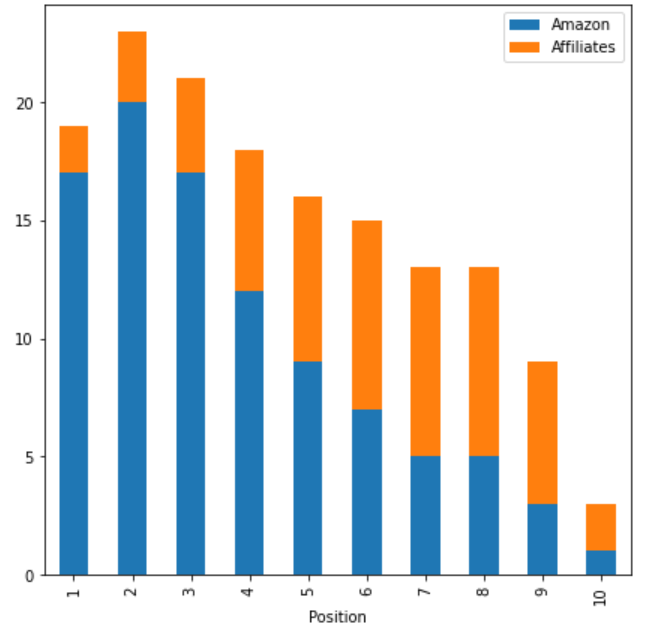
¿Qué podemos concluir con estos datos?
En pocas palabras, los datos muestran que, dentro de nuestro conjunto de 14.168 palabras clave, el mismo sitio web (o un sitio web que lo promocione) aparecerá en 20% de los casos, para los 4 primeros puestos.
Realmente es enorme, porque más del 50% de las búsquedas de productos comienzan en Amazon. Si a esto le sumamos la cuota de tráfico de Google que va a Amazon, acabaríamos con un 70% de cuota de mercado real. Si esto no es un monopolio, no sé qué sería.
A los afiliados: tened en cuenta que aunque Amazon siga siendo rentable para muchos de vosotros, no creo que vuelvan a subir las comisiones. Una parte de su éxito actual se ha conseguido gracias a la sinergia que ha existido durante años entre vosotros y ellos: vosotros proporcionabais los enlaces y el tráfico a cambio de una comisión sobre las ventas. Si crees que puedes gestionar un E-commerce, ve a por ello porque dependerás menos de un factor externo para asegurar la sostenibilidad de tu negocio.
A los competidores de Amazon: hay una oportunidad real para crear un competidor a su programa de afiliados y tratar de conseguir un pedazo de la cuota de mercado indicada en naranja en mi gráfico anterior.
Espero que te haya gustado el estudio y estaré encantado de leer tu opinión o feedback en la sección de comentarios. Si te interesa y como mencioné en la introducción, la metodología completa se explica a continuación.
Metodología completa
Si estás aquí, es que te interesa la metodología completa. Intentaré explicarla en profundidad, incluyendo parte del código Python que utilicé para manipular todo. Cualquier problema que se detecte en la metodología o en el proceso, no dudes en hacérmelo saber.
Selección de palabras clave
La lista se obtuvo siguiendo estos pasos:
- Extraer la lista de palabras clave de amazon.es en SEMRUSH. No creo que mi estudio tenga sesgo hacia Amazon al hacer esto, porque en realidad hay muy pocas palabras clave comerciales en las que Amazon no aparezca dentro de los primeros 100 resultados. Es una buena manera de obtener una lista extensa de palabras clave comerciales.
- Para asegurarme de excluir la mayoría de las palabras clave no comerciales, filtré la lista de palabras clave para incluir sólo las en las que estaría presente el módulo «Shopping».
- A continuación, excluí la mayoría de las palabras clave de marca utilizando el filtro “Excluir de SEMRUSH”.
- Y finalmente filtré todas las palabras clave con menos de 1.000 búsquedas al mes. Hice esta parte para terminar con un conjunto manejable de palabras clave, no una lista de 100.000 palabras clave. No tengo la infraestructura necesaria para realizar un estudio sobre un conjunto de datos de este tipo.
Extraer los datos de las SERPs de Google
He seguido lo que explica Carlos en este post, añadiendo únicamente una extracción personalizada para extraer las URLs de los resultados. Lo único importante aquí fue bajar la velocidad para evitar que Google bloqueara mi crawl. Lo hice a 0,1 URL/s. Así que sí, el rastreo duró casi 2 días.
Sé que hay formas más eficientes de hacerlo (usando proxy o APIs), pero no quería gastar dinero en ese estudio.
Resultados del rastreo
Basado en el primer rastreo, creé una lista de URLs únicas extraídas por Screaming Frog. El código era el siguiente:
#Load Pandas
import pandas as pd
#Load the export from Screaming Frog
x = pd.read_csv('list_mode_export.csv')
#Create an empty Series
concat = pd.Series()
#Loop all columns containing URLs we want to crawl
for i in range(1,11):
concat = pd.concat([concat,x['Links {}'.format(i)]])
#Remove empty rows because some queries have less than 10 results
concat = concat.dropna()
#Not mandatory because Screaming Frog does that anyway
concat = concat.drop_duplicates()
#Create the CSV we will feed to Screaming Frog
concat.to_csv('list.csv')El segundo rastreo incluyó 90.215 URLs únicas. Aquí no limité la velocidad y me bloquearon varios sitios web. Pero los revisé todos y ninguno de ellos eran afiliados, así que no impactó en mi análisis.
Configuré Screaming Frog para que sólo extrajera los enlaces externos, que es lo que realmente importa aquí. Me permitió acelerar el proceso ya que mi ordenador no es muy potente.
Análisis del rastreo
A continuación, puedes consultar el código utilizado para obtener toda la información mencionada en este artículo. He intentado comentarlo para que quede claro y explicar la lógica si no sabes leer código Python. Si tienes alguna duda, házmelo saber y estaré encantado en explicártelo.
Carga inicial de datos
#Import Pandas
import pandas as pd
#Import Matplotlib
import matplotlib.pyplot as plt
#Import Numpy
import numpy as np
#Load data from the first crawl
data = pd.read_csv('/content/drive/My Drive/Perso/list_mode_export.csv')
#Keep useful columns
data = data[[
'Address',
'Links 1',
'Links 2',
'Links 3',
'Links 4',
'Links 5',
'Links 6',
'Links 7',
'Links 8',
'Links 9',
'Links 10'
]]
#Retrieve the keyword from the Google's URL and set it as index
data['Keyword'] = data['Address'].str.extract('q=(.*)&rls')
data['Keyword'] = data['Keyword'].str.replace('+',' ')
#Just in case
data = data.drop_duplicates()
data = data.set_index('Keyword')
#Load data from the second crawl
outlinks = pd.read_csv('/content/drive/My Drive/Perso/all_outlinks.csv')
#Keep AHREF Link only
outlinks = outlinks[outlinks['Type']=='AHREF']
#Remove Amazon's websites
outlinks = outlinks[outlinks['Source'].str.contains('https://www.amazon')==False]
#Extract destination domain
outlinks['Domain'] = outlinks['Destination'].str.extract('^(?:https?:\/\/)?(?:[^@\/\n]+@)?(?:www\.)?([^:\/?\n]+)')
#Keep URLs with a link to Amazon
outlinks = outlinks[(outlinks['Domain']=='amazon.es')|(outlinks['Domain']=='amazon.com')|(outlinks['Domain']=='amzn.to')]Tabla de frecuencia del número de resultados de Amazon por consulta
def number_amazon_results(df):
df['Number_amazon_results'] = np.sum(df.str.contains('https://www.amazon'))
return df
#Apply the function
data = data.apply(number_amazon_results, axis = 1)
data['Number_amazon_results'].value_counts().sort_index()Número de resultados de búsqueda de Amazon
def number_amazon_search_results(df):
df['Number_amazon_search_results'] = np.sum((df.str.contains('https://www.amazon'))&(df.str.contains('k=')))
return df
#Apply the function
data = data.apply(number_amazon_results, axis = 1)
data['Number_amazon_search_results'].value_counts().sort_index()Cuota de mercado de Amazon por posición
#List we will use to gather our data
out = [['Position', 'Amazon']]
#Loop columns and retrieve rounded percentage of Amazon's market share per position
for i in range(1,11):
s = data['Links {}'.format(i)]
out.append([i,round(((s.str.contains('https://www.amazon').sum()*100)/len(s)))])
#Transform the list of lists in a DataFrame
out = pd.DataFrame(data=out[1:],columns=out[0])
#Plot it
out.plot(kind='bar',x='Position',y='%',figsize=(8,8))Cuota de mercado de Amazon y sus afiliados por posición
#See above
out2 = [['Position', 'Affiliates']]
#See above
for i in range(1,11):
s = data['Links {}'.format(i)]
out2.append([i,round(((s.isin(outlinks['Source'].unique()).sum()*100)/len(s)))])
#See above
out2 = pd.DataFrame(data=out2[1:],columns=out2[0])
#Pivot with the previous data
merge = out.merge(out2, on='Position')
#Set index
merge = merge.set_index('Position')
#Plot it
merge.plot(kind='bar',stacked=True, figsize=(7,7))