
If you’re making a living as a SEO consultant, I’m sure you’ve heard of JavaScript SEO, a part of technical SEO that allows Javascript-powered websites to be easy for search engines to crawl, render and index. If that is not the case, have a look at this outstanding guide by the Onely’s team.
As a summary, trying to SEO a JavaScript-powered website usually means that you need to pay attention to two things:
- Ensure that search engines and users can see the same things. To achieve this objective, you’ll often rely on SSR (Server-Side Rendering) as CSR (Client-Side Rendering) can lead to longer rendering queue.
- Ensure that key SEO components, such as links for instance, are not manipulated during the rendering process
Sounds straight-forward, but it is not always as easy as it sounds. Moreover, there is a specific issue that is often caused by JavaScript frameworks that I would like to explain today. Because it is not well-documented and can potentially kill your SEO. And is linked to what is called content rehydration.
What is content rehydration?
Content rehydration is a process that occurs when a website, built with a JavaScript framework, such as Angular or React, dynamically updates the content on a page without requiring a full-page refresh. This means that when a user navigates to a new page, the core structure of the page is loaded first, and then the dynamic content is loaded in real-time, improving the loading speed and user experience. This process is called rehydration because it “brings the content back to life” after it has initially been loaded. In Angular, this is achieved through the use of server-side rendering and client-side rendering techniques, which work together to provide a fast and seamless experience for the user.
Why using rehydration instead of relying only on SSR? Simply because it cuts the number of operations you require your server to do before sending the response to the user, while ensuring that the application is interactive quickly.
If you ensure that the main HTML components are included in your raw response sent by the server, we should be fine, shouldn’t we? Well, it’s not that simple. Let me tell you why.
What is the issue with content rehydration?
By default, this behavior comes with a major flaw, though.
It will add a script to the raw response sent by your server with all the required code to make the application dynamic. Out-of-the-box, this script can easily represent more than 90% of the total HTML size, as the example shown below from this tool. Nevertheless, 1.07 MB (270kb compressed) is not something that should have that much impact, isn’t it?
I used to believe that. Boy, little did I know how wrong I was.
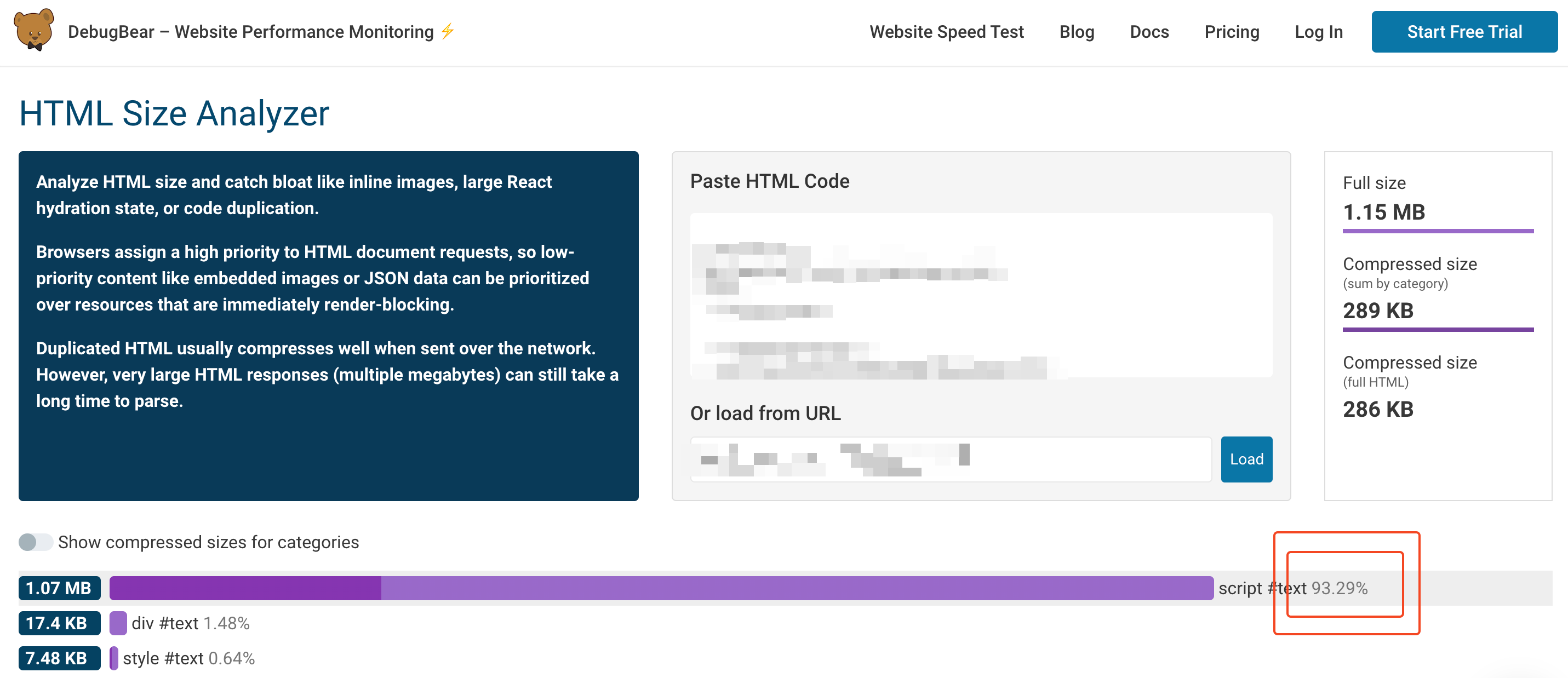
The issue is not linked to the size of the script itself, but what it means for search engines.
Google explains clearly in its documentation how it parses HTML document. The bottom-line is that once the raw response has been received, JavaScript files are executed to render the final HTML. The more JS code you have, the longer you’ll have to wait for your page to move from crawled to indexed.
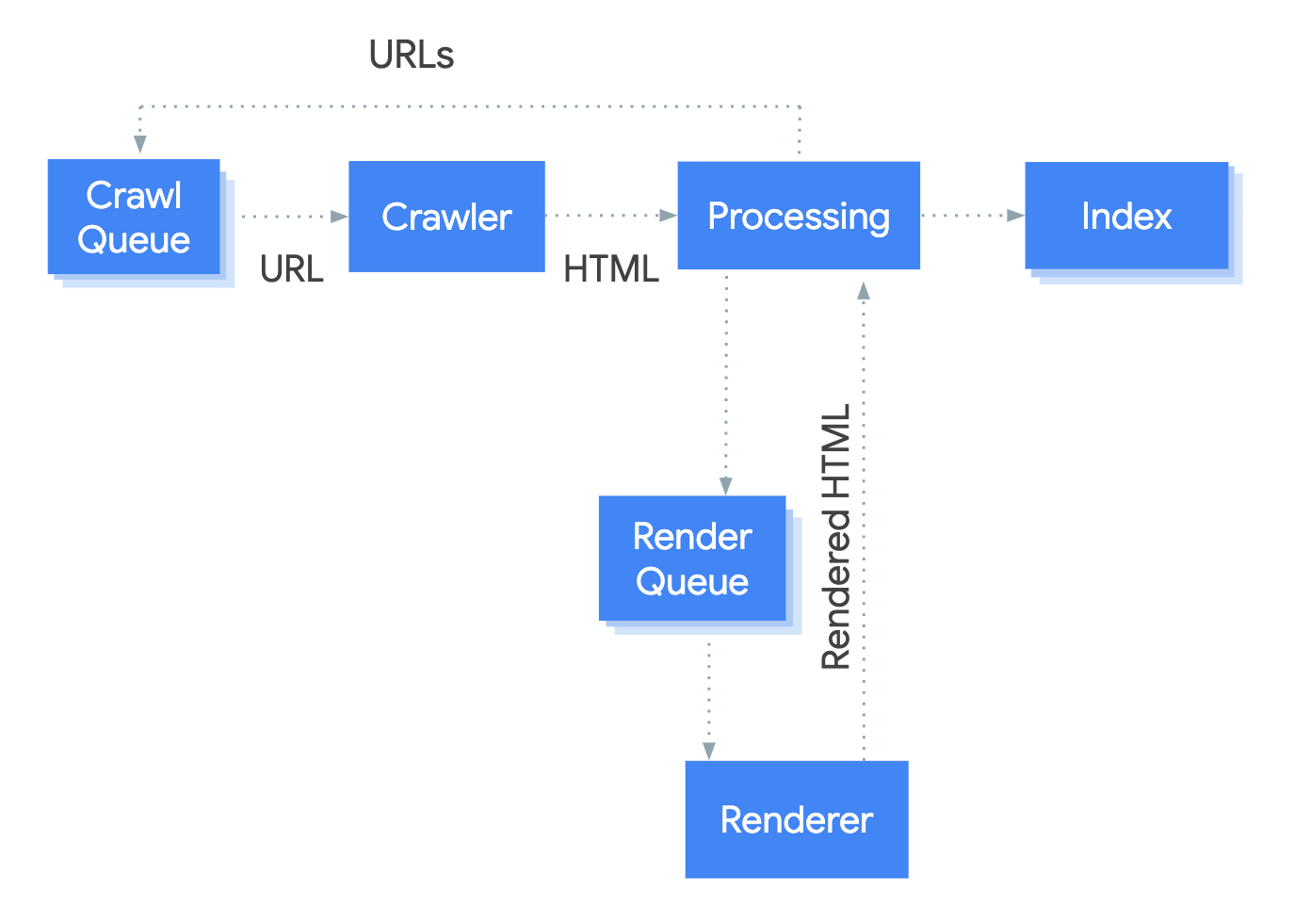
If you think from Google’s perspective, it makes complete sense. Indeed, this behavior rewards websites relying heavily on SSR, which decreases Google’s operating costs because parsing JavaScript at scale must be expensive. If you use out-of-the-box content rehydration, your website will take time to be indexed because every page will spend more time waiting in the rendering queue.
What impact can it have during a migration?
Scary, but what if I told you that there is a situation where it could actually be worse than that? Imagine that you are migrating from an old website to a Javascript-powered where you need to change your URL structure. Not an uncommon situation if you think about it.
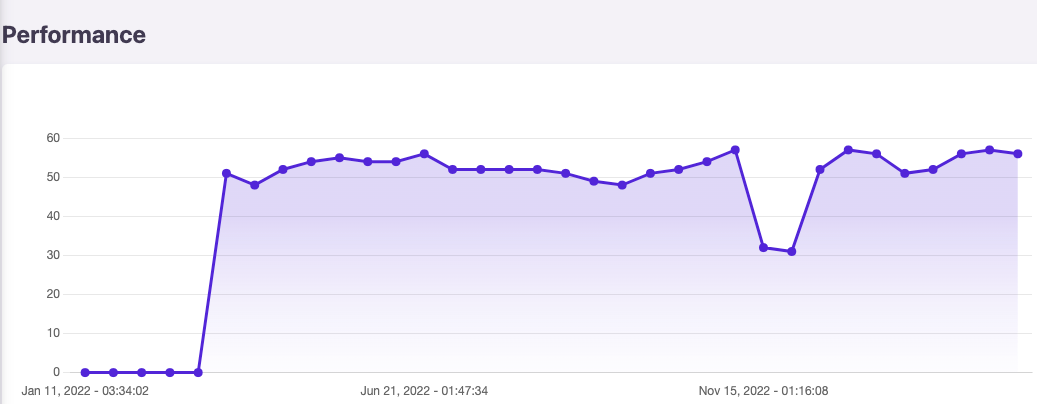
Well, you’ll face the following situation in countless keywords: a sudden (but temporary) drop followed by a new position that is very likely to be lower than the previous one, at least in the short term.
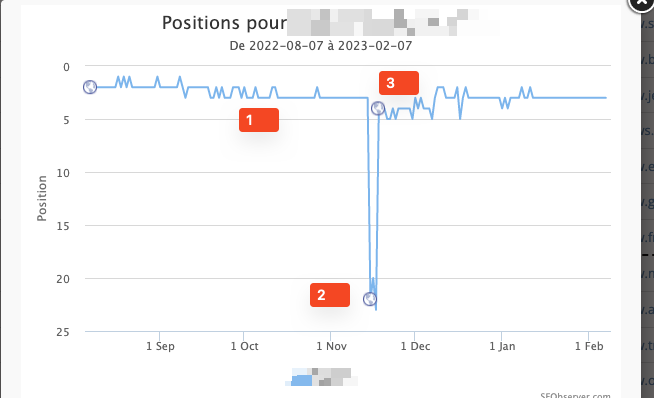
Why you may ask? Let me explain:
- During the phase 1 (in my previous screenshot), we observe changes that are completely normal, as a result page can evolve daily
- During the phase 2, a couple of days after the redirection is implemented, the position suddenly drops.
The strange thing about this phase is that the ranked URL is neither the old URL nor the new one. It’s another one, usually not matching the user intent. My initial reaction was simple: Google is broken and is not handling redirections as well as it used to.

Easier to blame a third party when the issue actually comes from your side, right? What was happening was actually simple:
- Google detected the 301 redirection and added the new URL in its crawl queue
- Due to the content rehydration on the new pages, Google took forever to process the content
- At some point, it removed the old URL from its index (respecting the 301) but as the new URL was not processed yet, it picked the closest matching URL for a while
- When the new URL is finally processed, the new URL got back to (almost) the old rank
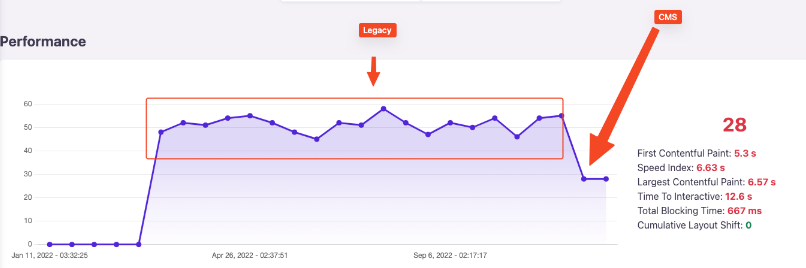
The difference for the position between phase 2 & 3 is explained by the difference in speed. While CWV are a tie-breaker, if your new page is significantly slower than the old one (content hydration will impact all CWV metrics but CLS) and given the resources Google will spend on your page, you’ll very likely not recover your initial rank.
How can you solve it?
Content rehydration is not bad because it comes with major advantages I already explained at the beginning of the article. Nevertheless, out-of-the-box, the script includes a lot of information you are not using in your application. The trick is then to optimize it by asking your team to exclude the information you are not using.
Too simple to be true? Well, that’s precisely what was done here and after the initial drop, script size was reduced by 50-75% and performance level went back to the initial level instantly. And rankings started to increase just after that.
Conclusion
While having a huge script doesn’t necessarily affect only JavaScript-powered website, I’ve realized that this issue affects a lot of them, even it is often not detected until a migration happens, At the end of the day, we often look at the total HTML size, but not its breakdown by tag.
If you’re dealing with a JavaScript-powered website, make sure you know what content rehydration is and explain to your team how it needs to be optimized to avoid breaking your SEO.