Analizar a tus competidores es esencial.
Es una forma bastante eficaz de entender qué están haciendo los demás mejor que tú y si ya han implementado una parte de la estrategia que tu equipo y tú acabas de idear.
Sin embargo, uno de los principales retos para realizar un benchmark SEO relevante es cómo puedes analizar a tu competencia a escala, es decir, sin tener que mirar su informe Ahrefs o SEMRUSH línea por línea, especialmente cuando trabajas y compites contra grandes marcas.
En este artículo, te mostraré cómo puedes comparar tu contenido con el de tus competidores rápidamente. No cubriré todo el proceso de benchmark, sino que, explicaré cómo puedes acelerar una parte del mismo.
Define tu competencia
El primer paso es esencial porque debes asegurarte de centrarte sólo en tus principales competidores, y no desperdiciar esfuerzos en sitios web que no valen la pena rastrear. Ten en cuenta que estamos hablando de tus competidores en línea, y la lista puede diferir de lo que sueles percibir como su competencia.
Pondré un ejemplo: si trabajas para una marca de supermercados como Wallmart, no incluirías en tu benchmark a ningún competidor que no venda productos online. No tendría ningún sentido.
Si trabajas para un pure player, deberías estar acostumbrado a ello, pero a menudo a los negocios tradicionales les cuesta entender que la competencia online y offline pueden ser diferentes.
Te aconsejo que intentes elaborar una lista corta (alrededor de 5), pero si compites con diferentes sitios web en función del segmento, obviamente puedes definir más.
Obtén una lista de URLs
Una vez definida tu lista, el siguiente paso es recopilar información sobre tu contenido y el de tus competidores. No queremos exportar sólo sus informes orgánicos de SEMRUSH o Ahrefs, porque también queremos saber qué contenidos no les están funcionando.
Para conseguir esa información, existen dos opciones (la última es la más eficiente):
- Rastrear sus webs con Screaming Frog, Oncrawl o el software con el que te sientas más cómodo. Yo prefiero el primero ya que puedes ajustar la configuración sobre la marcha, pero realmente depende de ti. Si decides seguir mi sugerencia, asegúrate de tener la siguiente configuración en Spider > Configuration > Crawl, ya que no queremos recoger información inútil para nuestro benchmark, especialmente cuando tengamos que rastrear sitios web de más de 1M de URLs. Cuando el rastreo esté completo, simplemente exporta el informe de URLs internas.
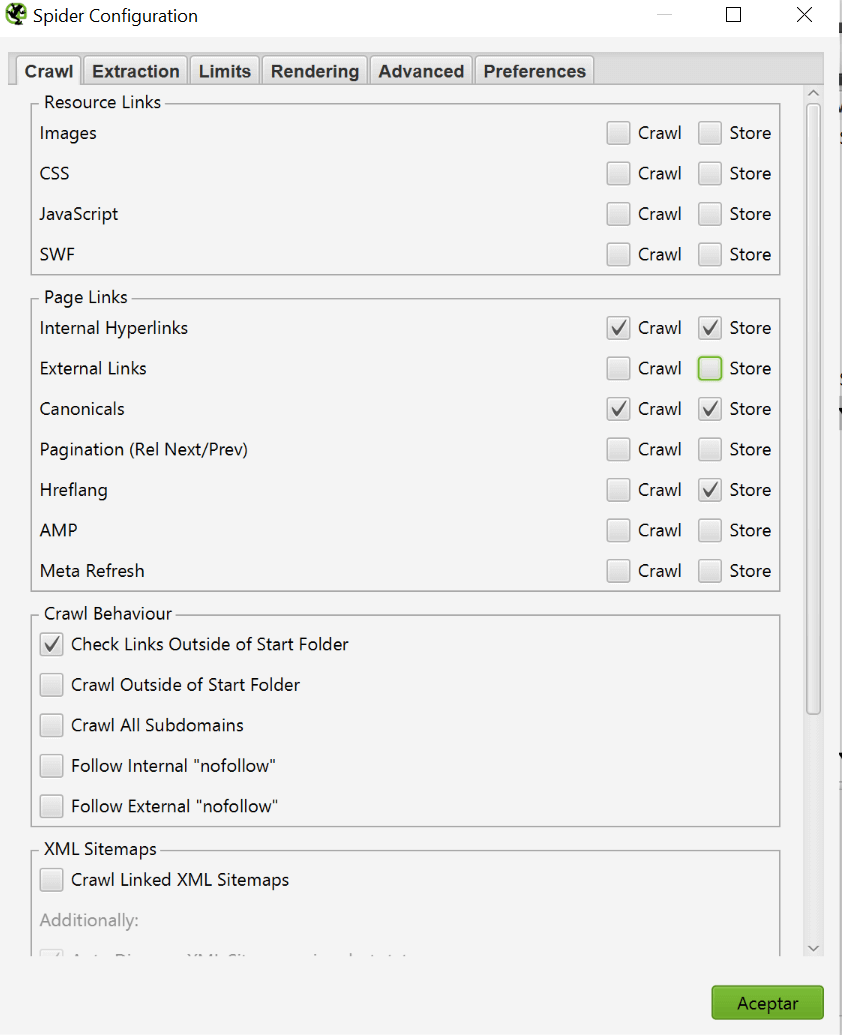
- Si sabes que tus competidores han configurado sus sitemaps correctamente, sólo tienes que introducir la URL en la herramienta y copiar-pegar la lista, ni siquiera tienes que rastrearlos.
Si no estás seguro de cómo hacerlo, sigue estos pasos:
- Haz clic en “Mode” y selecciona “List”
- En Upload, selecciona Descargar mapa del sitio XML
- Introduce la URL del sitemap y espera a que Screaming Frog detecte todas las URLs
- Copia y pega el texto en un archivo CSV, elimina las líneas inútiles del principio y del final y sustituye «Found » (con un espacio en blanco) por «» (nada) y ya está
Tendrás que repetir el mismo proceso para todos y cada uno de los competidores y guardar los datos en un archivo Excel. También necesitarás un crawl de tu sitio web, pero supongo que ya debes tener uno 🙂
Datos de tráfico de SEMRUSH
Una vez que tengas todos los datos de rastreo, debemos obtener las estimaciones de tráfico de SEMRUSH. De nuevo, puedes utilizar otra herramienta si lo deseas.
Ve a Investigación Orgánica, luego a la pestaña Páginas y luego exporta todo.
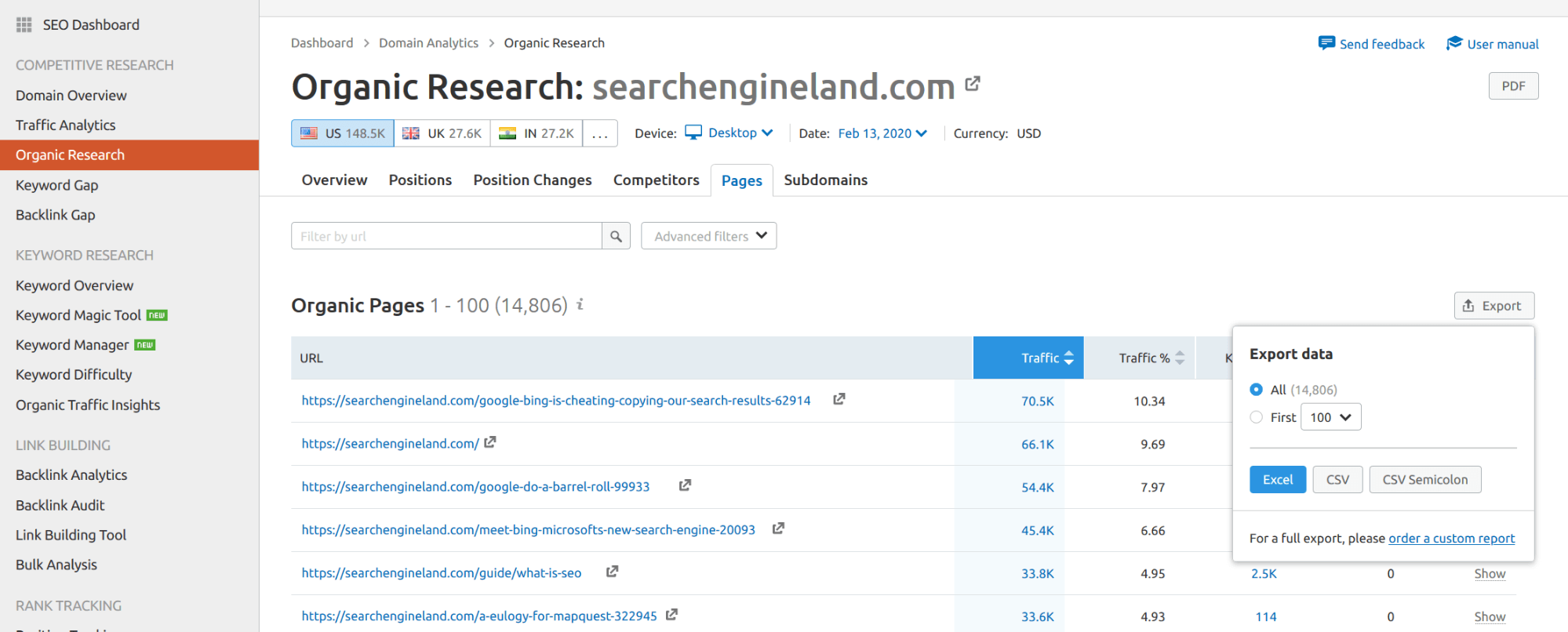
Súper sencillo, ¿cierto?, pero apenas estamos empezando. Yo aconsejaría utilizar los datos de SEMRUSH para tu sitio web también, incluso si tienes acceso a tus datos reales. ¿Por qué? Porque comparar las estimaciones con los datos reales puede sesgar tu análisis.
Clasificar las URLs
Si quieres comparar grandes sitios web entre sí, primero tienes que clasificar las URLs porque no puedes mirar sus contenidos individualmente. Lo que haremos es tratar de encontrar un patrón en la estructura de las URLs y crear grupos para nuestros competidores y para nosotros mismos.
Te daré un ejemplo concreto: imagina que necesitas clasificar las URL del sitio web francés de Getaround. Veamos 2 URLs de la lista que deberías mirar:
https://fr.getaround.com/location-voiture/france/type/familiale https://fr.getaround.com/location-voiture/paris
Deberíamos ser capaces de categorizar todas las URLs que siguen el mismo patrón como Coche/Tipo y Coche/Ciudad por ejemplo. Podemos identificar estos dos patrones con un simple REGEX y luego asignar una categoría a nuestras URLs.
Podríamos hacerlo en Excel o en Google Sheets, pero yo prefiero usar Python porque ofrece la posibilidad de trabajar con conjuntos de datos enormes sin preocuparse de que el ordenador se congele por completo. Es cuestión de preferencia personal pero puedes aplicar la misma técnica en cualquier otro lenguaje con el que te sientas cómodo: Python es una herramienta que me gusta por ser más eficiente, pero lo que realmente importa es el resultado.
El código es sencillo y te lo voy a explicar paso a paso.
Primero, tendrás que importar Pandas y Numpy, los únicos paquetes que utilizaremos.
import pandas as pd
import numpy as npA continuación, tendremos que importar nuestros datos de rastreo de Screaming Frog y los datos de tráfico de SEMRUSH:
internal = pd.read_csv('path/to/your/file.csv')
traffic = pd.read_csv('path/to/your/file.csv')Debes repetir el mismo proceso para ti y tus competidores, utilizando diferentes nombres de variables. Si has rastreado el sitio web y no sólo has exportado las URL del mapa del sitio, tu archivo puede incluir un montón de columnas inútiles que no necesitamos para este análisis. El mismo comentario se aplica al archivo SEMRUSH.
Podemos entonces fusionar estos dos archivos para saber cuántas sesiones (estimadas por SEMRUSH) está generando cada URL. El código es bastante sencillo, acorde con lo que hemos visto hasta ahora:
merge= internal.merge(traffic,left_on='Address',right_on='URL')Hacemos un left merge porque no queremos eliminar de nuestra variable interna las URLs que no tienen tráfico según los datos de SEMRUSH. ¿Por qué?porque nuevamente necesitamos saber qué está funcionando actualmente y qué no. ¿Qué sentido tiene replicar una estrategia que no funciona?
Una vez hecha esta fusión, necesitamos clasificar las URLs. Podemos hacerlo ejecutando el siguiente código:
conditions = [
(internal['Address'].str.contains("/location-voiture/france/type/.\*$",regex=True)),
(internal['Address'].str.contains("/location-voiture/[a-z]+$",regex=True))
]
choices = [
'Car/Type',
'Car/City'
]
merge['pagetype'] = np.select(conditions, choices, default='None')Lo que hacemos básicamente es crear una serie de condiciones para que coincidan con los diferentes tipos de páginas que tiene un sitio web específico. Se pueden utilizar condiciones simples o basadas en REGEX. Luego creamos un array de valores: si la primera condición del array de condiciones es respetada, entonces el valor de la nueva columna que queremos crear será también el primero, y así sucesivamente. El concepto es bastante sencillo, ¿verdad? Esta magia es posible gracias a la parte np.select, donde añadimos un valor por defecto.
Una vez hayas hecho esto para tu sitio web y el de tus competidores, es posible que quieras saber cuántas URLs tiene cada sitio web por tipo de página. Es una forma rápida de dirigir su análisis hacia tipos de página específicos. Lo que hacemos básicamente es contar el número de URLs para cada tipo de página en nuestros DataFrames, y luego fusionarlos todos.
company1_overview = company1_internal['pageType'].value_counts().to_frame().reset_index().rename(columns={'pageType':'N'})
company2_overview = company2_internal['pageType'].value_counts().to_frame().reset_index().rename(columns={'pageType':'N'})
company3_overview = company3_internal['pageType'].value_counts().to_frame().reset_index().rename(columns={'pageType':'N'})
overview = company1_overview.merge(company2_overview,on='index',how='outer',suffixes=('_company1','_company2'))
overview = overview.merge(company3_overview,on='index',how='outer').rename(columns={'N':'N_company3'})
overview.sort_values(by='index')
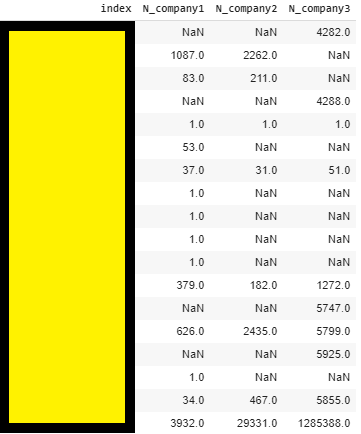
El resultado debería ser algo parecido a la imagen que se muestra a continuación, lo que te permitirá detectar rápidamente una discrepancia entre tu y tus competidores. Aquí no estamos analizando el tráfico, pero sí queremos comprobar si un competidor tiene 10.000 URLs para una categoría en la que nosotros sólo tenemos 100, por ejemplo. En tal situación, si están generando un montón de URLs inútiles, o nos estamos perdiendo algo. En ambos casos, es bueno saberlo 🙂
Analizar los resultados
En nuestro ejemplo, lo que podemos ver es que hay una gran discrepancia entre estas 3 empresas para el último tipo de contenido, con la empresa 1 teniendo 3932 páginas, el competidor 2 29.331 y la empresa 3 alrededor de 1.300.000. Es una diferencia que definitivamente vale la pena analizar.
Para compararlas, tenemos que ser capaces de emparejar el contenido entre los competidores y luego extraer lo que la empresa 1 tiene que la empresa 2 no tiene, por ejemplo. Lo que básicamente hay que hacer es encontrar, dentro de la URL, una parte para realizar dicha acción.
Imaginemos ahora que queremos emparejar contenidos entre dos de las mayores empresas de alquiler de coches del mundo: Sixt y Avis. En el paso anterior, habríamos creado una categoría llamada «Coche/Ciudad», y deberíamos tener estas dos URLs dentro de ella
https://www.sixt.com/car-rental/usa/dallas/ https://www.avis.com/en/locations/us/nv/las-vegas/
Mirándolas, sé que ambas están usando la ciudad como última carpeta, por lo tanto si puedo extraerla, puedo hacer coincidir ambos contenidos. Aplicando un simple .str.extract(), podemos crear una nueva columna para realizar dicha coincidencia.
Para ambas, podemos utilizar el siguiente código:
car_city = internal[internal['pageType']=='Car/City']
car_city['ID'] = car_city['Address'].str.extract('.*\/(.*)\/$', regex=True)Ahora podemos saber cuál es el solapamiento de contenidos de ambas empresas:
len(pd.Series(list(set(company1_car_city['ID']).intersection(set(company2_car_city['ID'])))))Pero, lo más importante, es que podemos extraer contenido que no tenemos pero que está funcionando bien para un competidor.
company2_car_city[company2_car_city['ID'].isin(company1_car_city['ID'])==False].sort_values(by='Traffic',ascending=False)Esta parte es impresionante porque si está trabajando para Avis, te dirá qué ciudades no tiene, pero para las que Sixt sí está recibiendo tráfico. Detectar las ciudades que faltan y para las que no tiene una página ahora puede ser complicado porque se trata de conjuntos de datos enormes. Utilizando esta técnica, al menos se pueden detectar rápidamente las más importantes.
He aplicado esta técnica en varios proyectos y nos ha permitido detectar contenidos clave para determinados tipos de páginas que no estaban cubiertas por nuestros sitios web cuando pensábamos que sí lo estaban. También descubrimos nuevas y agradables oportunidades que ni siquiera habíamos considerado en primer lugar.
A continuación, puedes ver las categorías que ellos tienen pero tú no, y así sucesivamente. Te quedarás con un análisis en profundidad de tus competidores en términos de tráfico orgánico.
Conclusión
Como he indicado al principio, no he incluido todas las cosas que hay que mirar durante un benchmark, pero me gusta este enfoque porque es simple, repetible y te permite tener una visión bastante buena de tus competidores y empezar a luchar con ellos en palabras clave que no habías pensado en primer lugar.