Whether you’re just starting out with your online business or you decided to revamp your SEO strategy from scratch to be more visible to your potential customers, analyzing your competitors is essential.
It’s a rather efficient way to understand what the others are doing better than yourself and if they already implemented a part of the strategy your team and yourself have just come up with.
However, one of the main challenges to perform a relevant SEO benchmark is how can you analyze your competition at scale, meaning without having to look at their Ahrefs or SEMRUSH report line by line, especially when you are working for and competing against big brands.
In this article, I’ll show you how you can benchmark your content against your competitors quickly. I won’t cover the full benchmark process but explain how you can speed up a part of it.
Define your competition
The first step is essential because you need to be sure to only focus on your main competitors, and not waste effort on websites that are not worth tracking. Please note that we are talking about your online competitors, and the list may differ from what you usually perceive as being your competition.
Let me give an example: if you are working for a supermarket brand like Wallmart, you wouldn’t include in your benchmark any competitor that doesn’t sell groceries online. It wouldn’t make any sense.
If you are working for a pure player, you should be used to it but often brick-and-mortar business have a hard time understanding that online and offline competition are often different.
I would advise to try to come up with a short list (around 5) but if you are competing against different websites depending on the segment, you can obviously define more. Don’t hesitate to include some small companies if you are a big brand, as it’s easier for them to implement things and can quickly be on your tails on some queries.
Get a list of URLs
Once your list is defined, the next step is to gather information about your content and your competitors’. We don’t want to only export their SEMRUSH or Ahrefs organic reports, because we also want to know which contents are not working for them.
To get that information, two options (the latter being the most efficient):
- Crawl their websites using Screaming Frog, Oncrawl or whatever software you are the most comfortable with. I prefer the former as you can adjust configuration on-the-go, but it’s really up to you. If you decide to follow my suggestion, please be sure to have the following configuration under Spider > Configuration > Crawl because we don’t want to gather useless information for our benchmark, especially when we may have to crawl websites over 1M URLs. When the crawl is complete, just export the internal URL report.
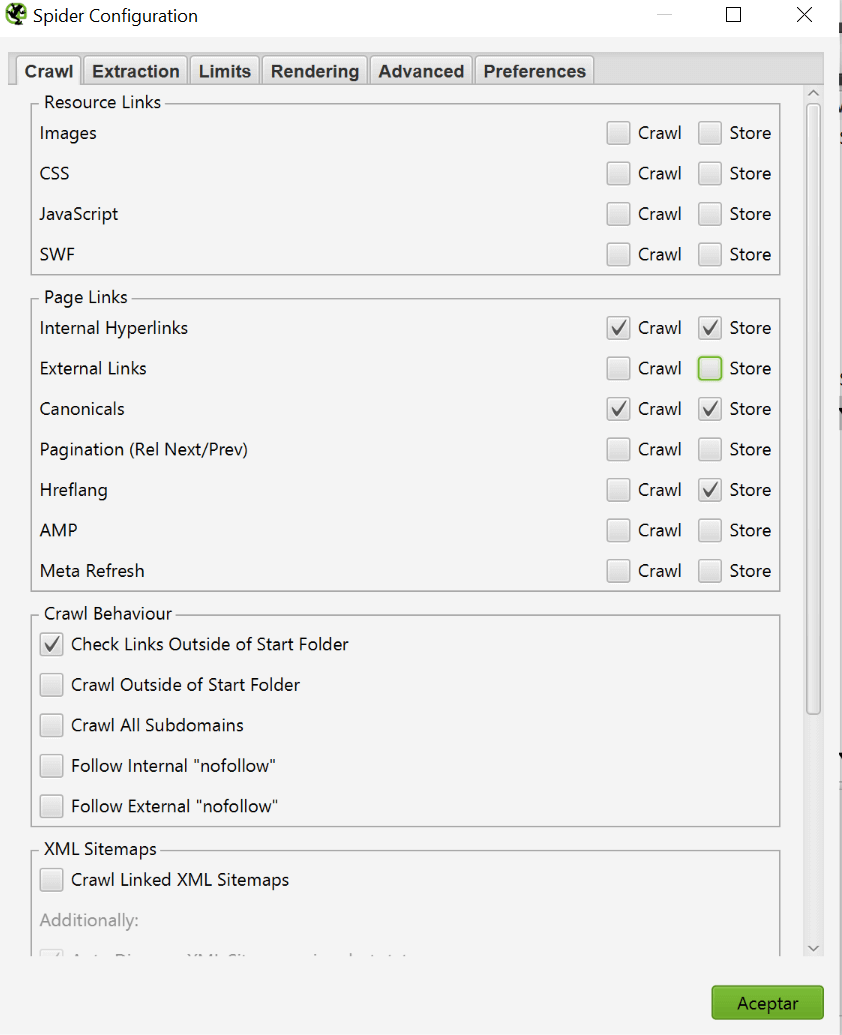
- If you know that your competitors have set up their sitemaps correctly, just enter the URL in the tool and copy-paste the list, you don’t even have to crawl them.
If you are not sure how to do it, please follow these steps:
- Go to Mode and select List
- Under Upload, select Download XML Sitemap
- Introduce the sitemap URL and wait for Screaming Frog to detect all URLs
- Copy-paste the text into a CSV file, remove the useless lines at the beginning and at the end and replace “Found “ (with a blank space) by “” (nothing) and you are done
You will have to repeat the same process for each and every competitor and store the data in an Excel file. You will also need a crawl from your website, but I assume that you should already have one 🙂
SEMRUSH Traffic data
Once you have all the crawl data, we must get the traffic estimates from SEMRUSH. Again, you can use another tool if you want to.
Go to Organic Research, then the Pages tab and then export everything.
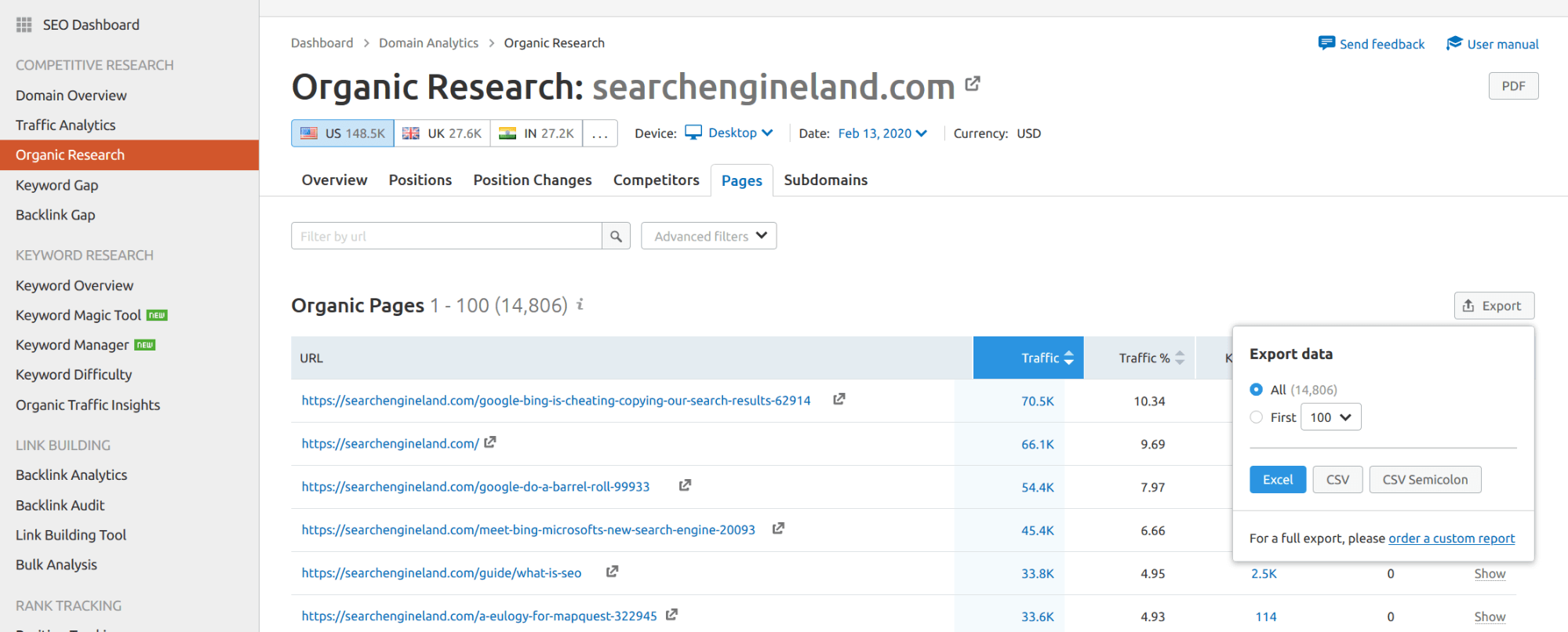
Super simple, right? Yes, but we are just getting started, so let’s follow with what you are looking for! I would advise to use SEMRUSH data for your website as well, even if you have access to your real data. Why? Because comparing estimates with real data may skew your analysis.
Classify URLs
If you want to compare big websites between themselves, you need to classify URLs first because you can’t look at their contents individually. What we’ll do is try to find a pattern in the URL structure & create groups for our competitors and ourselves.
Let me give you a concrete example: imagine that you need to categorize the URLs from the Getaround’s French website. Let’s have a look at 2 URLs from the list you would look at:
https://fr.getaround.com/location-voiture/france/type/familiale https://fr.getaround.com/location-voiture/paris
We should be able to categorize all URLs following the same pattern as Car/Type and Car/City for instance. We can identify these two patterns with a simple REGEX and then assign a category to our URLs.
We could do that under Excel or Google Sheets but I prefer to use Python because it offers the possibility of working with huge datasets without worrying about your computer to freeze completely. It’s a matter of personal preference but you can apply the same technique in any other language you are comfortable with: Python is a tool I like to be more efficient, but what really matters is the outcome.
The code is simple and I’ll explain it to you, step by step.
First, you will have to import Pandas and Numpy, the only packages we will use.
import pandas as pd
import numpy as np
We will then need to import our crawl data from Screaming Frog & traffic data from SEMRUSH:
internal = pd.read_csv('path/to/your/file.csv')
traffic = pd.read_csv('path/to/your/file.csv')
You must repeat the same process for yourself and your competitors, using different variable names obviously. If you crawled the website and not just exported the sitemap URLs, your file may include a lot of useless columns we don’t need for this analysis. The same comment applies to the SEMRUSH file.
We can then merge these two files to know how many sessions (estimated by SEMRUSH) each URL is generating. The code is pretty simple, aligned with what we’ve seen so far:
merge= internal.merge(traffic,left_on='Address',right_on='URL')
We do a left merge because we don’t want to remove, from our internal variable, URLs with no traffic based on SEMRUSH data. Why? Again, because we need to know what is currently working and what is not. What’s even the point of replicating a looser strategy?
Once this merge is done, we need to classify the URLs. We can do just that by running the following code:
conditions = [
(internal['Address'].str.contains("/location-voiture/france/type/.\*$",regex=True)),
(internal['Address'].str.contains("/location-voiture/[a-z]+$",regex=True))
]
choices = [
'Car/Type',
'Car/City'
]
merge['pagetype'] = np.select(conditions, choices, default='None')
What we basically do is creating an array of conditions to match different page types that a specific website has. You can use simple or REGEX based conditions. We then create an array of values: if the first condition of the conditions array is respected, then the value of the new column we want to create will be the first as well, and so on. The concept is pretty simple, isn’t it? This magic is possible thanks to the np.select part, where we add a default value as well.
Once you do that for your website and your competitors’, you may want to know how many URLs each website has per page type. It’s a quick way to direct your analysis towards specific page types. What we basically do is to count the number of URLs for every page type in our DataFrames, and then merge them all.
company1_overview = company1_internal['pageType'].value_counts().to_frame().reset_index().rename(columns={'pageType':'N'})
company2_overview = company2_internal['pageType'].value_counts().to_frame().reset_index().rename(columns={'pageType':'N'})
company3_overview = company3_internal['pageType'].value_counts().to_frame().reset_index().rename(columns={'pageType':'N'})
overview = company1_overview.merge(company2_overview,on='index',how='outer',suffixes=('_company1','_company2'))
overview = overview.merge(company3_overview,on='index',how='outer').rename(columns={'N':'N_company3'})
overview.sort_values(by='index')
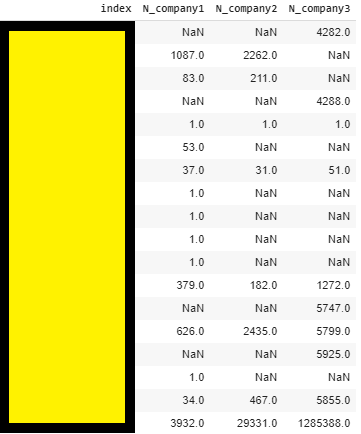
The result should be something like the image shown below, allowing you to quickly detect a discrepancy between yourself and your competitors. We are not analyzing traffic here but we nonetheless want to check whether a competitor has 10.000 URLs for a category where we have just 100 for instance. In such situation, whether they are generating a bunch of useless URLs, or we are missing something. In both cases, it’s good to know 🙂
Analyze results
In our example, what we can see is that there is a big discrepancy between these 3 companies for the last content type, with company 1 having 3932 pages, competitor 2 29.331 and company 3 around 1.300.000. That’s a difference definitely worth looking at.
To compare them we need to be able to match content between competitors and then extract what company 1 has that company 2 hasn’t for instance. What you basically need to do is find, within the URL, a part to perform such action.
Let’s imagine now that we want to match contents between two of the biggest car rental companies worldwide: Sixt & Avis. In the previous step, we would have created a category called “Car/City”, and we should have had these two URLs within it:
https://www.sixt.com/car-rental/usa/dallas/ https://www.avis.com/en/locations/us/nv/las-vegas/
By looking at them, I know that both are using the city as the last folder, hence if I can extract it, I can match both contents. By applying a simple .str.extract(), we can create a new column to perform such matching.
For both of them, we can use the following code:
car_city = internal[internal['pageType']=='Car/City']
car_city['ID'] = car_city['Address'].str.extract('.*\/(.*)\/$', regex=True)
We can now know what is the content overlap for both companies:
len(pd.Series(list(set(company1_car_city['ID']).intersection(set(company2_car_city['ID'])))))
But, most important, we can extract content that we don’t have but performing well for a competitor.
company2_car_city[company2_car_city['ID'].isin(company1_car_city['ID'])==False].sort_values(by='Traffic',ascending=False)
This part is awesome because if you are working for Avis, it will tell you which cities you don’t have, but for which Sixt is actually getting traffic. Detecting missing cities for which you don’t have a page at the moment can be tricky because you are dealing with huge datasets. By using this technique, you can at least detect the most important ones quickly.
I applied this technique in several projects and it allowed us to detect key content for specific page types not being covered by our websites when we thought they were. We also discovered nice new opportunities that we don’t even had considered in the first place.
You can then look at the categories they have but you don’t and so on. You will be left with an in-depth analysis of your competitors in term of organic traffic.
Conclusion
As I indicated at the beginning, I didn’t include all the things you need to look at during a benchmark, but I like this approach because it is simple, repeatable and allows you to have a pretty good overview of your competitors and start fighting with them on keywords you hadn’t thought about in the first place.