
Una de las razones por las que una empresa puede empezar a buscar una agencia en SEO o un freelance es porque han metido la pata en una migración y necesitan solucionarlo cuanto antes.
Cuando trabajaba en SEOCOM, uno de los mayores clientes con los que he trabajado empezó a colaborar con nosotros tras una migración catastrófica que se gestionó sin tener en cuenta el SEO, que en realidad suponía una parte enorme de su tráfico total.
Esta no es una situación muy cómoda ya que puedes enfrentarte a una pérdida de información que es importante para llevar a cabo una migración decente. Sí, es posible que todavía tenga los datos de Google Analytics, pero ¿qué pasa con la posibilidad de comparar la versión antigua del sitio web y la nueva? Además, a veces la estructura de la URL puede ser confusa y no muy útil para entender cómo era el contenido.
En esta situación, archive.org es una herramienta que puedes aprovechar para arreglar la situación. Veamos cómo.
¿Qué es archive.org?
Para aquellos que aún no sepan qué es archive.org (también llamado wayback machine), se trata simplemente de una herramienta cuya misión principal es guardar archivos históricos de la web. Por ejemplo, puedes buscar grandes sitios web, como Facebook, Amazon o incluso Google, y ver cómo eran hace algunos años.
La herramienta no tiene la misma infraestructura (y dinero) que los GAFA, por lo que si se trata de un sitio web pequeño, es probable que no esté incluido en su base de datos. O si tienes suerte, sólo una pequeña parte.
Si se trata de un sitio web más grande, las probabilidades están a tu favor y deberías poder acceder a una buena parte del contenido. Una buena noticia para ti: ¡es completamente gratis y no tendrás que pagar ni un céntimo! ¿No es genial?
Si nunca has utilizado la herramienta, sólo tienes que seguir estos pasos:
- Ir a https://archive.org/
- Introduce una URL en el formulario de búsqueda.
- Elige una fecha y ve cómo era el contenido ese día
¿Cómo podemos utilizarla para el SEO?
Desde la perspectiva del SEO, hay muchos casos de uso para estos servicios. Vamos a enumerar algunos de ellos:
- Recuperar una lista de URLs antiguas para comprobar que las redirecciones se han realizado correctamente.
- Extraer el contenido antiguo de un dominio que acabas de comprar.
- Comprobar la evolución del sitio web de tus competidores a lo largo de los años para entender por qué les va tan bien ahora.
Dejaremos de lado el último escenario, que quería mencionar de todos modos porque en realidad es el primer uso que le di a esta herramienta, y te guiaré a través del proceso de los otros dos puntos.
Extraer y filtrar los datos en bruto de la API
Archive.org tiene una API que puedes usar para recuperar directamente la lista completa de URLs para un dominio específico. Sólo tienes que usar la siguiente URL, actualizando el dominio por él que quieras trabajar.
http://web.archive.org/cdx/search/cdx?url=minderest.com*&output=txt
Sin embargo, ten cuidado porque si no utilizas el parámetro limit, el sistema devolverá todos los datos históricos, que pueden ser bastantes en función del dominio que introduzcas
Si necesitas aplicar algún tipo de filtro (basado en la fecha, por ejemplo), consulta la documentación completa en GitHub.
Ahora, deberías ver en tu navegador el siguiente contenido:
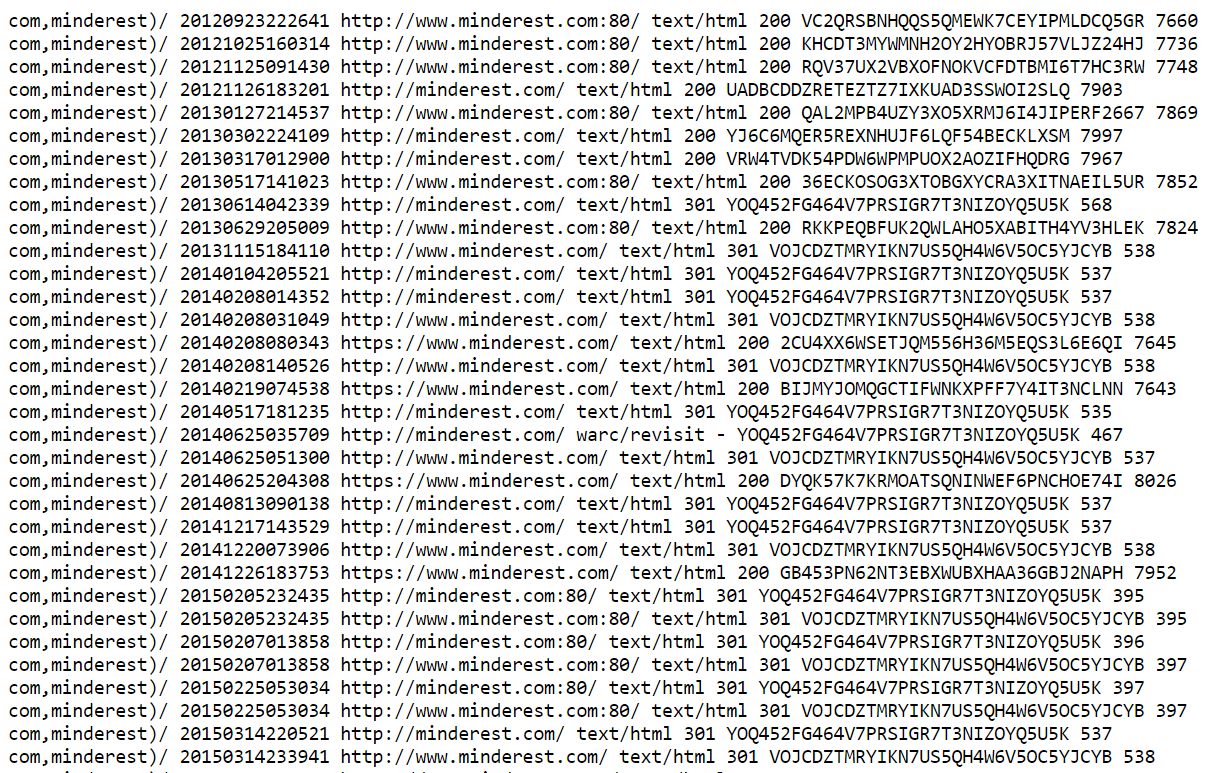
Este archivo contiene una lista de todas las instantáneas almacenadas por archive.org. Una instantánea se refiere a una URL específica y a una fecha específica, lo que explica por qué ves muchos duplicados aquí. Manejaremos estos casos en un próximo paso, no te preocupes.
Guarda el archivo y cárgalo en Google Sheets utilizando la función de importación (Archivo > Importar)
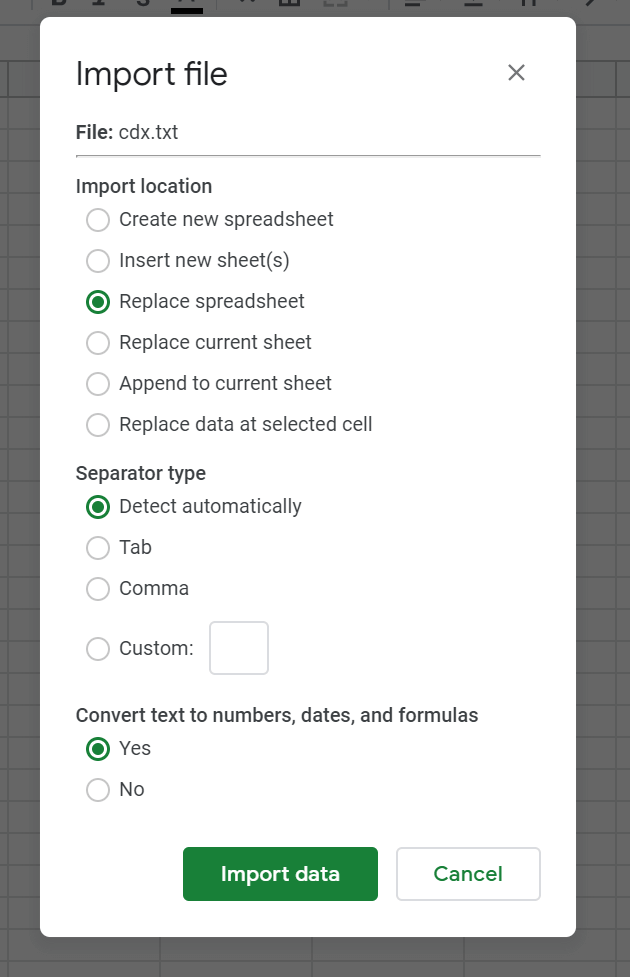
Ahora es el momento de limpiar un poco nuestro archivo:
- Si tus datos no están separados por columnas porque la detección automática no ha funcionado (lo que suele ocurrir), selecciona la columna A y haz clic en Datos > Dividir texto en columnas y elige «espacio» como separador.
- Filtra tus datos por tipo de contenido (columna D) para eliminar todo lo que no sea texto/html. Aquí no nos interesan los css, js y otros tipos de archivos.
- Elimina todo excepto las columnas C (URLs).
- Elimina el «:80» incluido en algunas de sus URLs aplicando un simple find & replace a la columna
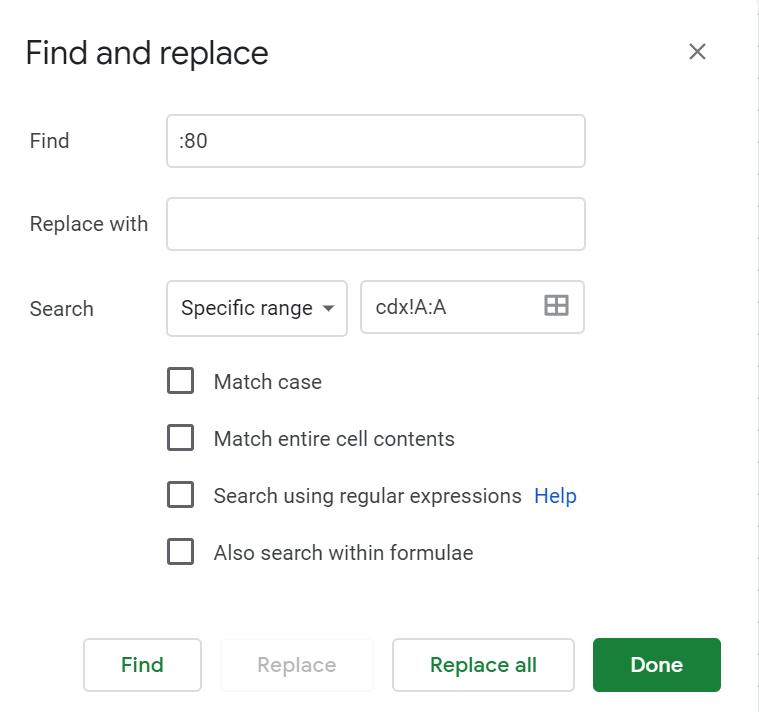
- Por último, elimina los duplicados seleccionando la columna A y haciendo clic en Datos > Eliminar duplicados
Eso es todo, ahora tienes tu lista de URLs que vamos a usar. Si necesitas auditar muchos sitios web, te aconsejo crear un script para realizar estos pasos para todos ellos, de lo contrario podría ser bastante lento. Si sólo tienes una, esta es la forma más rápida en mi opinión.
Analizar las URLs
Bien, en este punto deberías analizar tus URLs usando Screaming Frog o cualquier crawler con el que quieras trabajar para obtener los códigos de estado actuales de estas URLs.
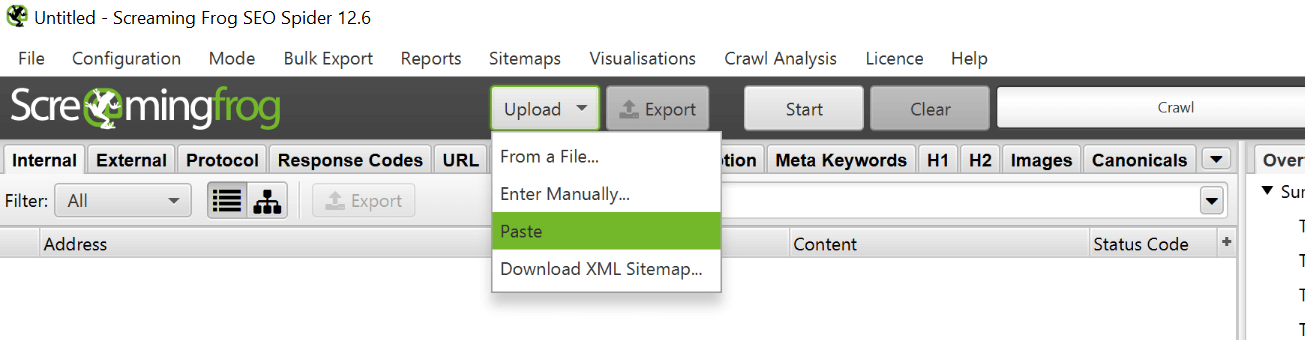
Deberías obtener varios códigos de respuestas diferentes, pero yo diría que al menos deberías obtener un montón de 200, 301 y 404. Sin embargo, no podemos analizarlos todos, ya que puede tratarse de un sitio web enorme y hay que priorizar el trabajo.
Durante una migración, no tienes que redirigir todo tu contenido, sólo el contenido que vale la pena migrar. ¿Qué es un contenido que vale la pena migrar? ¿Genera tráfico? ¿Tiene enlaces externos? ¿Sirve para la conversión? Si la respuesta a cualquiera de estas preguntas es afirmativa, entonces debes migrar este contenido. Al combinar tu lista de URLs con los datos de SEMRUSH, Ahrefs y Analytics (por nombrar algunos), deberías poder definir cuáles merecen la pena entrar en tu plan de migración.
Ahora imaginemos que observas la siguiente redirección en Screaming Frog: /post/123456 ==> /post/how-to-tie-a-tie. La redirección puede ser correcta, pero no puedes estar seguro porque la antigua estructura sólo incluía una serie de números.
Para comprobar que la redirección haya sido definida correctamente, necesitas echar un vistazo a lo que era el contenido de /post/123456/. Puedes repetir el proceso que explicamos al principio, pero puede llevar bastante tiempo seguir este tedioso proceso para un gran número de URLs. Tenemos que encontrar una manera de obtener la URL directa a la última instantánea disponible.
Si miramos la documentación de la API, hay una forma de obtener esta información utilizando el endpointl https://archive.org/wayback/available. Echemos un vistazo al contenido que obtenemos si lo utilizamos:
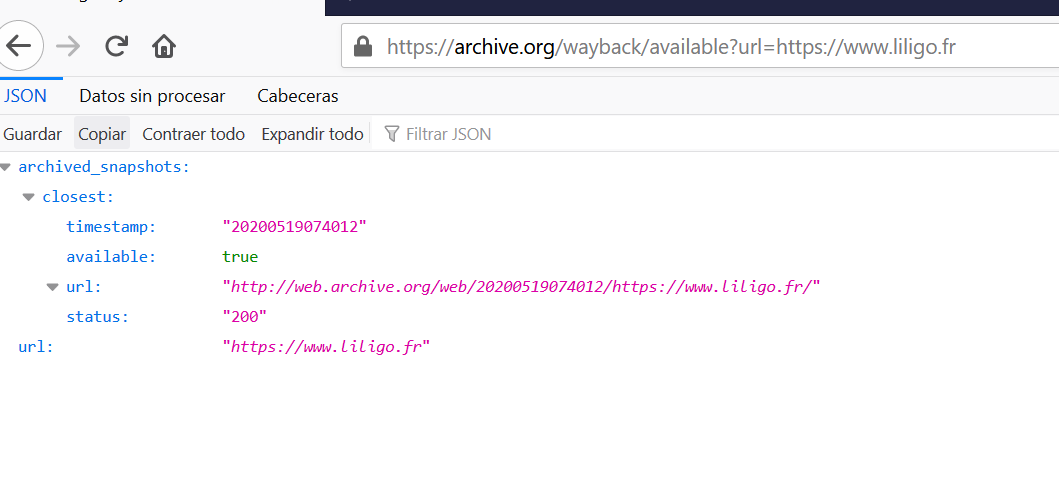
Podemos recuperar la última instantánea disponible, lo que nos ahorraría mucho tiempo. Genial, pero ¿cómo extraer esta información a escala? por suerte, Google Sheets nos cubre las espaldas. Sólo tienes que seguir estos pasos:
- Haz clic en Complementos > Obtener complementos
- Busca «JSON» e instala el siguiente complemento. Añadirá una nueva función, IMPORTJSON(), a Google Sheets para manejar fácilmente archivos JSON directamente en Sheets
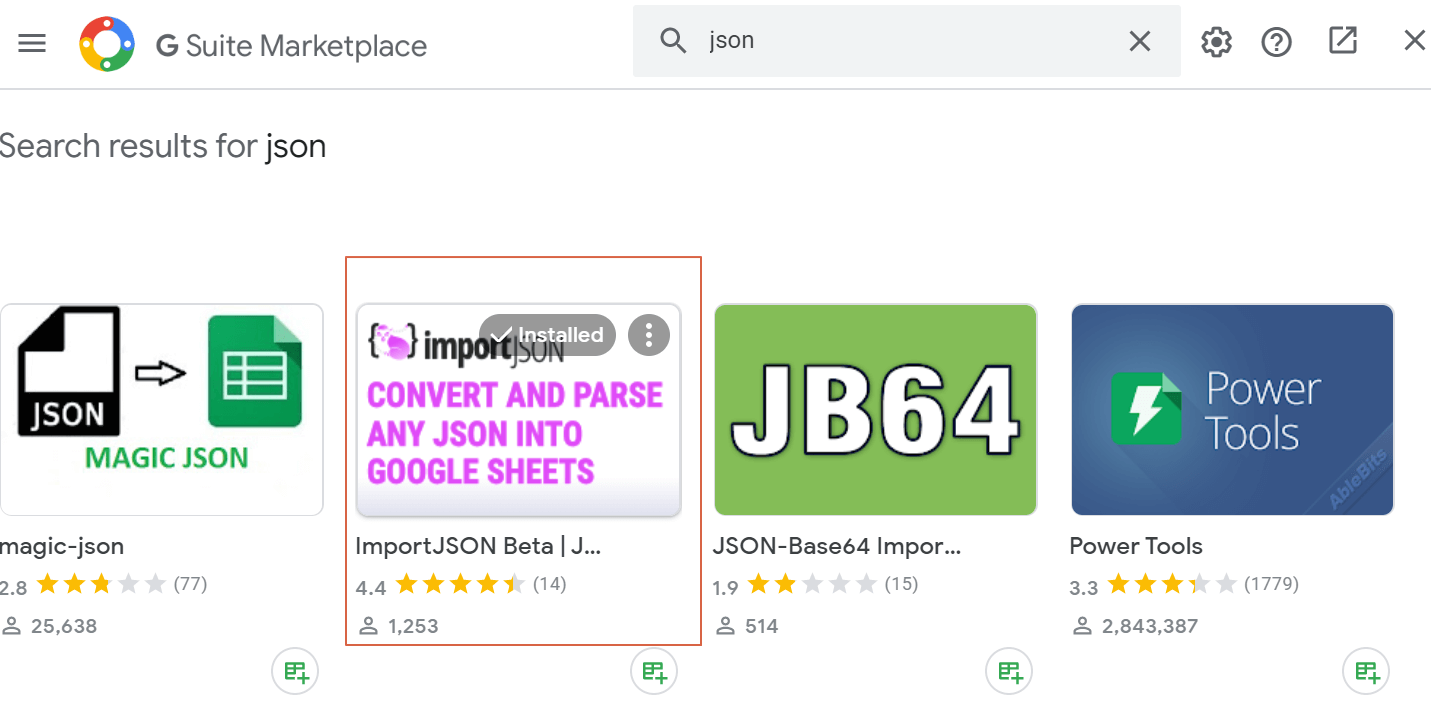
- Carga de nuevo tu hoja de Google Sheets y haz clic en Complementos > Importar JSON > Activar
- Utiliza la siguiente fórmula: =IMPORTJSON(«http://archive.org/wayback/available?url=»&A1,»/archived_snapshots/closest/url»). No olvides actualizar «A1» si tu URL está en otra columna.

En la columna C, obtendrás el enlace directo a la última instantánea disponible. ¿No es increíble? Ahora puedes comprobar si se han implementado correctamente las redirecciones para las URLs cuyas estructuras no permiten adivinar cuál era el contenido original.
Si trabajas con Python, aquí tienes el equivalente:
#Libraries
import requests
import pandas as pd
import json
#You should have a list of URLs here, similar to the A column in Sheets.
urls =
#API endpoint for the last available snapshot
api_endpoint='http://archive.org/wayback/available'
#List where we will store the snapshot URLs
out = []
for url in urls:
#Create the dictionnary with parameters
parameters = {
'url':url
}
#Make the requests
r = requests.get(api_endpoint,params=parameters).json()
#Retrieve url for the snapshot
extraction_url = r['archived_snapshots']['closest']['url']
snapshot_url = requests.get(extraction_url)
out.append(snapshot_url)
Extraer contenidos antiguos
Cuando miras todos los datos extraídos de la API de archive.org, puedes encontrarte con casos en los que los contenidos que hubieran tenido que ser migrados no lo han sido. Si estamos hablando de una pequeña lista, puedes utilizar la interfaz de usuario de archive.org y básicamente copiar/pegar el contenido. ¿Pero qué pasa si estamos hablando de una sección completa o de una gran lista de URLs?
Una vez más, hay una manera de acelerar el proceso, ¡vamos a verlo!
La mayoría de los sitios web utilizan algún tipo de sistema de plantillas, y se puede identificar una sección de una plantilla con una clase o un id. Por ejemplo, los posts publicados en Search Engine Land – un famoso blog sobre motores de búsqueda – utilizan la misma clase CSS para el contenedor de contenido principal:

Si miras el código fuente de una instantánea del mismo sitio web en archive.org, encontrarás la misma clase, ya que está almacenada sin ser modificada, lo cual es genial.
Por lo tanto, tu tarea es básicamente identificar un selector CSS (o Xpath) del contenido que quieres extraer de la url instantánea de archive.org que obtuvimos en el paso anterior. De nuevo, puedes hacerlo desde Google Sheets.
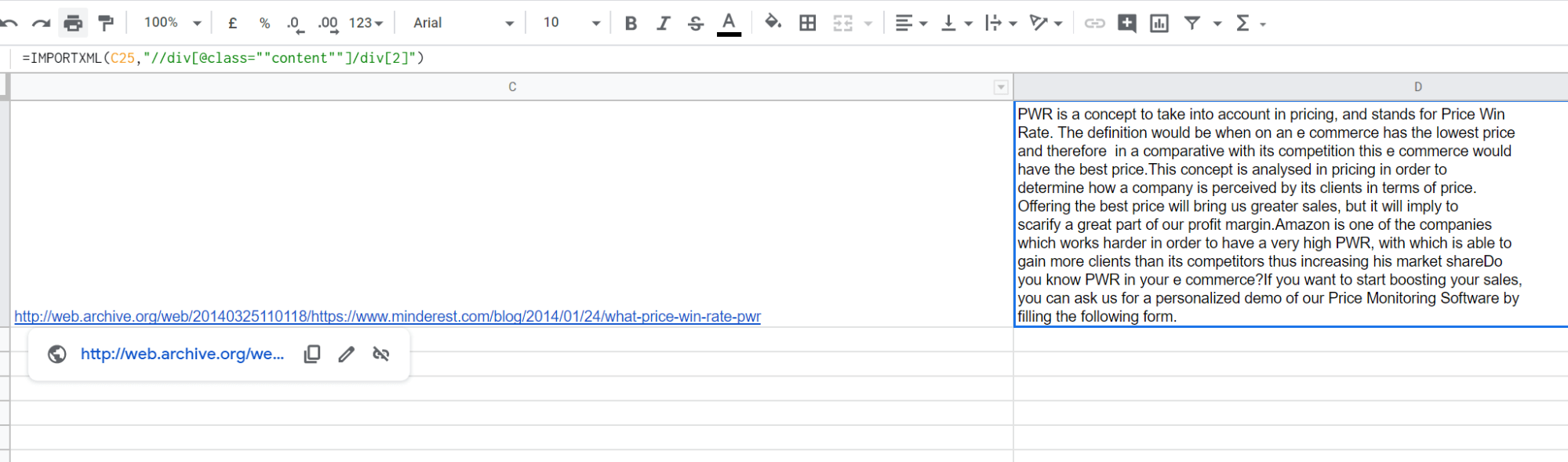
Para el sitio web que usamos como ejemplo desde el principio, podemos imaginar que queremos extraer el contenido de algunas entradas del blog que no han sido migradas. Investigando un poco, nos habríamos dado cuenta de que el contenido principal está incluido en la segunda <div> dentro de una div con la clase CSS «content».
Con esta información, extraemos el contenido directamente en Sheets, utilizando la función IMPORTXML(), indicando:
- La URL de la que queremos extraer el contenido, que en nuestro caso es la URL de la instantánea
- El Xpath del contenido que queremos recuperar
Y voilà, obtenemos el contenido directamente en Sheets. Bastante sencillo, ¿verdad?
Ten en cuenta que encontrar un Xpath genérico para extraer sólo el contenido que queremos (y no el nombre del autor, los comentarios, etc…) puede ser a veces un reto, pero de todas formas te ahorrarías mucho tiempo, así que merece totalmente la pena pasar un rato para encontrar el Xpath perfecto 😉
Una vez recuperado el contenido, puedes añadirlo de nuevo a la web de tu cliente. Puedes copiar y pegar el contenido porque era el suyo. No habrá problema de contenido duplicado aquí.
Si trabajas con Python, sólo tienes que usar la librería beautifulsoup para conseguir exactamente lo mismo.
Conclusión
Como hemos visto, archive.org es una herramienta poderosa que puede ser aprovechada para varias tareas relacionadas con el SEO. Aunque su interfaz de usuario es lenta, podemos utilizar su API o la función integrada de Google Sheets para utilizarla a escala y así ahorrar tiempo. Un gran ahorro de tiempo en ocasiones es la única opción que tenemos para ver y entender lo que pasó en el pasado.