
One of the reasons a company may start to look for a SEO agency or freelance is because they messed up a migration and they need to solve it as soon as possible.
When I was working @SEOCOM, one of the biggest client I have ever worked with actually landed after a castrophic migration that was handled without taking into account the SEO, which actually accounts for a huge piece of their total traffic.
This is not a very comfortable situation because you may face a loss of information that is important to carry out a decent migration. Yes you may still have the Google Analytics data, but what about being able to compare the old version of the website and the new one? Moreover, sometimes the URL structure can be fuzzy and not very helpful to understand what the content looked like.
In such situation, archive.org is a tool that you can leverage to fix the situation. Let’s see how !
What is archive.org?
For those wo may not know yet what archive.org (also called wayback machine) is, it is simply a tool whose main mission is to provide historical archives for the web. You can for instance search for big websites, like Facebook, Amazon or even Google, and see what they looked like some years ago.
The tool doesn’t have the same infrastructure (and money) than the GAFA, hence if you are dealing with a small website, it is likely that it is not included in their database. Or if you are lucky, just a small part of it.
For bigger website, the odds are in your favor and you should be able to access a good part of it. Good news for you: it is completely free and you won’t have to pay a penny ! How cool is that?
If you have never used the tool, just follow these steps:
- Go to https://archive.org/
- Enter an URL in the search form.
- Pick a date and see what the URL looked like this day
How can we use it for SEO purpose?
From a SEO perspective, there a lot of use cases for this services. Let’s list some of them:
- Recover a list of old URLs to check that the redirections have been implemented correctly
- Extract old content from a domain you just bought
- Check your competitors’ website evolution over the years to understand why they are doing so good now
We will leave out the last scenario, that I wanted to mention anyway because it is actually the first use I had for this tool, and I will walk you through the process of the two other bullet points.
Extract and filter the raw data from the API
Archive.org has an API that you can use to retrieve directly the full list of URLs for a specific domain. Just go to the following URL, updating the domain by the one you want to work with.
http://web.archive.org/cdx/search/cdx?url=minderest.com*&output=txt
Be careful though because if you don’t use the limit parameter, the system will return all the historical data, which can be quite large based on the domain you input
If you need to apply some kind of filtering (based on the date for instance), see the full documentation on GitHub.
At this point, you should see in your browser the following content:
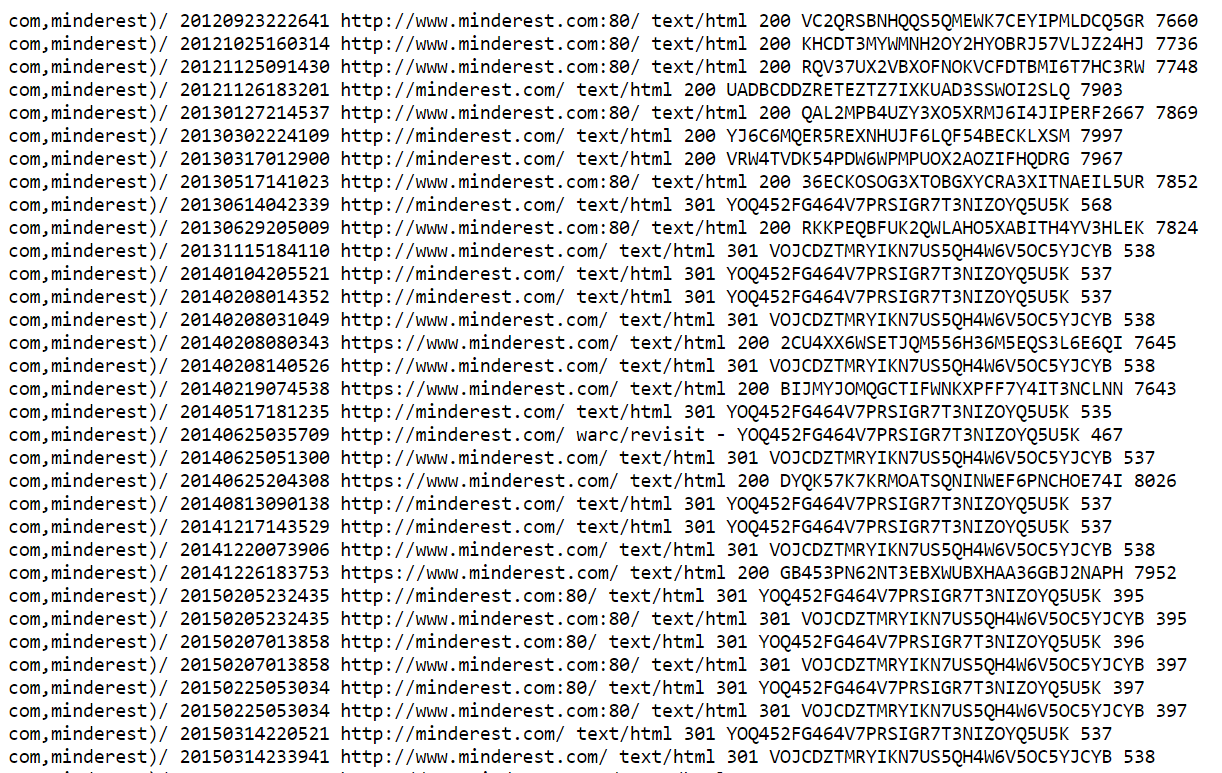
This file contains a list of all snapshots stored by archive.org. A snapshot refers to a specific URL and a specific date, which explains why you see a lot of duplicates here. We’ll handle these cases in a next step, don’t worry about it.
Save the file and load it in Google Sheets using the buil-in import functionality (File > Import)
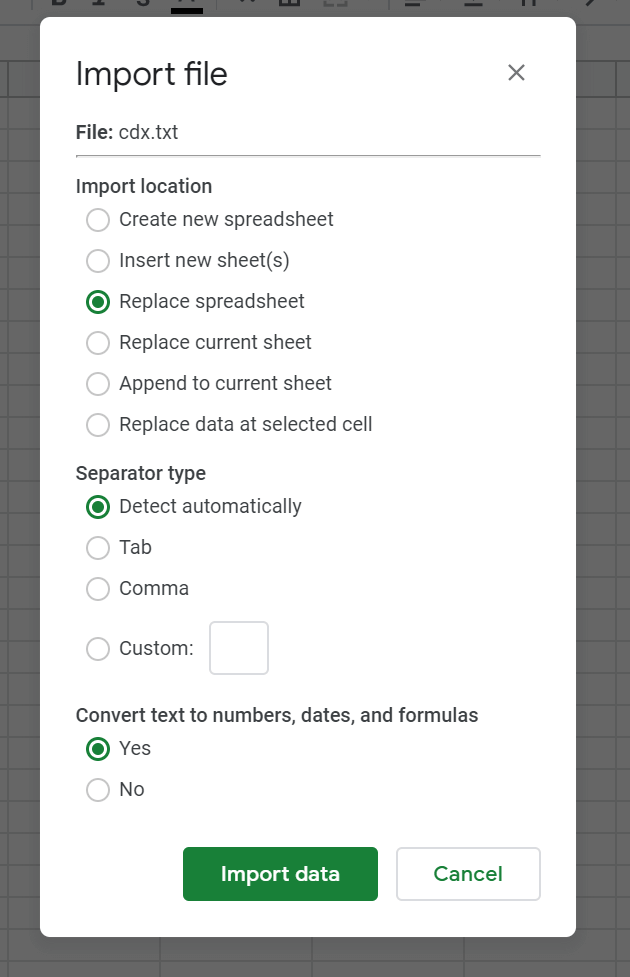
It’s now time to clean a little bit our file:
- If your data are not separated by column because the automatic detection didn’t work (which is often the case), select the A column and click on Data > Split texte to columns and choose “space” as the separator
- Filter your data by content type (D column) to remove everything but text/html data. We are not interedted by css, js and other file types here.
- Remove everything but the C columns (URLs).
- Remove the “:80” included in some of your URLs by applying a simple find & replace to the column
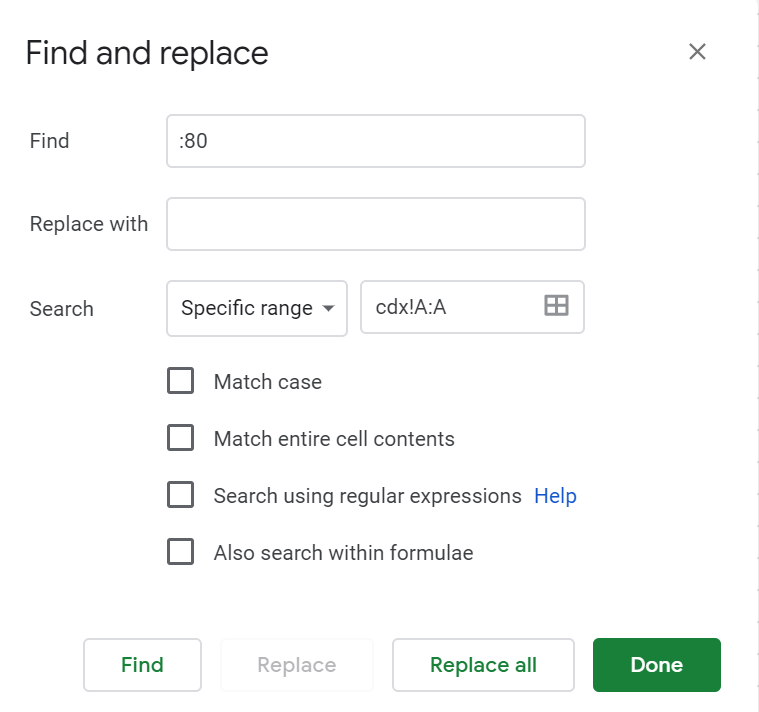
- Last but not least, remove duplicated by selecting the A column and clicking on Data > Remove duplicates
That’s it, you have your list of URLs we are going to deal with. If you need to audit a lot of websites, I would advise to create a script to to these steps for you for all of them, otherwise it could be quite time-consuming. If you just have one, this is the quickiest way in my opinion.
Audit the URLS
Ok, so at this point you should audit your URLs using Screaming Frog or any crawler you want to work with to get the current status codes of these URLs.
We should get a several different response codes, but I’s say that you should at least get a bunch of 200, 301 & 404. We can’t look at all of them though, because you may be dealing with a huge website and you have to prioritize your work.
During a migration, you don’t have to redirect all your content, just the content worth migrating. What is a content worth migrating? Does it generate traffic? Backlinks? Conversion? Pageviews that may imply that it is part of the customer journey? **If you answer yes to any of these questions, then you must migrate this content. **By merging your URLs list with SEMRUSH, Ahrefs & Analytics data (to name just a few), you should be able to define which ones were worth migrating and worth looking at during your audit.
Now let’s imagine that you observe the following redirection in Screaming Frog: /post/123456 ==> /post/how-to-tie-a-tie. The redirection may be correct, but you can’t be sure because the old structure included only a serie of numbers.
To check that the redirection has been defined correcly, you need to take a look at what the content of /post/123456/ was. You could repeat the process we explained at the beginning, but it can quite time-consuming to follow this tedious process for a large bunch of URLs. We need to find a way of getting the direct URL to the last available snapshot.
If we look at the API documentation, there is actually a way of getting this information using the https://archive.org/wayback/available endpoint. Let’s have a look at the content we get if we use this endpoint using a specific URL:
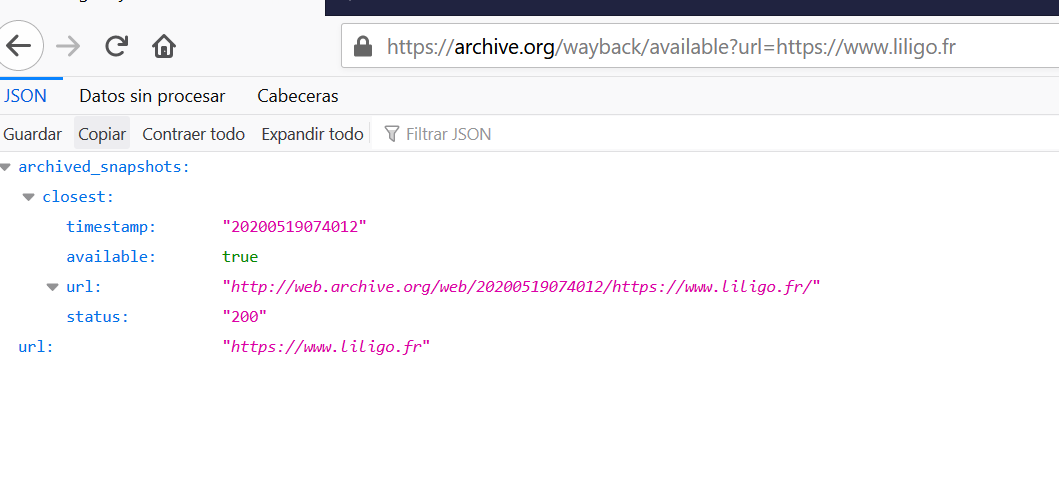
We can retrieve the last available snapshot, which would save us a lot of time. Great, but how do you extract this information at scale? Luckily, Google Sheets has our back. Just follow these steps:
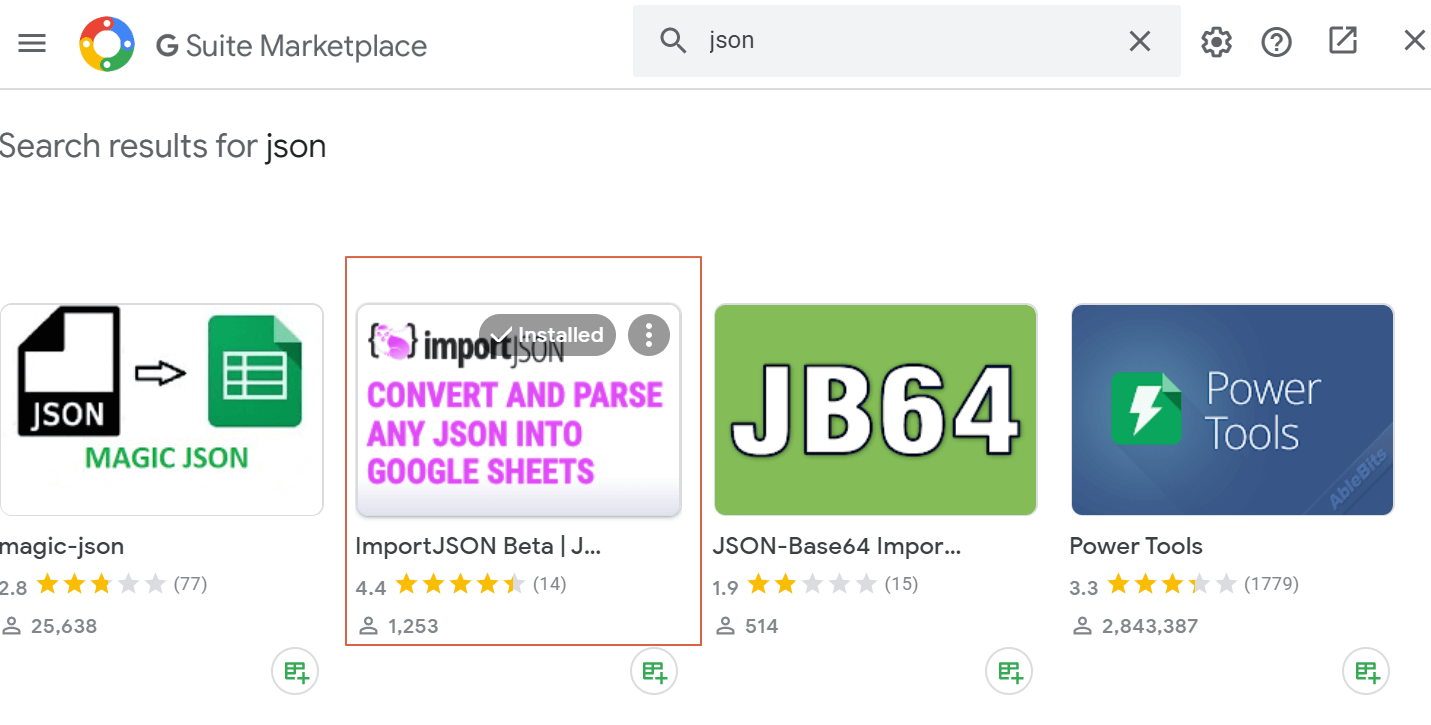
- Click on Add-ons > Get Add-ons
- Search for “JSON” and install the following add-on. It will add a new function, IMPORTJSON(), to Google Sheets to handle easily JSON file directly in Sheets
- Refresh your Google Sheets documents and click on Add-ons > Import JSON > Activate
- Use the following formula: =IMPORTJSON(“http://archive.org/wayback/available?url=”&A1,”/archived_snapshots/closest/url”). Don’t forget to update “A1” if your URL is in another column.

In the C column, you wil get the direct link to the last availabla snapshot. Isn’t that amazing? You can now check whether redirections where the structure doesn’t allow you to guess what the content was about have been correctly implemented.
If you are working with Python, here is the equivalent:
#Libraries
import requests
import pandas as pd
import json
#You should have a list of URLs here, similar to the A column in Sheets.
urls =
#API endpoint for the last available snapshot
api_endpoint='http://archive.org/wayback/available'
#List where we will store the snapshot URLs
out = []
for url in urls:
#Create the dictionnary with parameters
parameters = {
'url':url
}
#Make the requests
r = requests.get(api_endpoint,params=parameters).json()
#Retrieve url for the snapshot
extraction_url = r['archived_snapshots']['closest']['url']
snapshot_url = requests.get(extraction_url)
out.append(snapshot_url)
Extract old content
When you look at all the data extracted from the archive.org API, you may face cases where contents worth migrating haven’t. If we are talking about a small list, you can use the archive.org UI and basically copy/paste the content. But what if we are talking about a full section or a large list of URLs?
Again, there is a way of speeding up the process, let’s walk you through it !
Most websites use some kind of templating system, and you can identify a section of a template by a class or an id. For instance, posts published in Search Engine Land – a famous blog on search engines – use the same CSS class for the main content container:
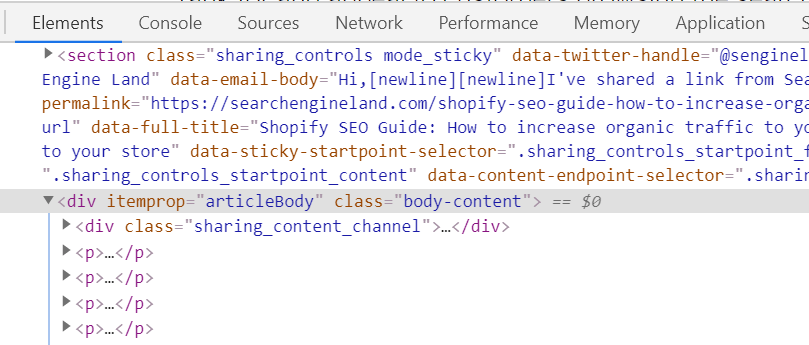
If you look at the source code of a snapshot of the same website in archive.org, you will find the same class because it is stored without being modified, which is great.
Therefore, your task is basically to identify a CSS selector (or Xpath) to target the content you want to extract from the archive.org snapshot url we get in the previous step. Again, you can do everything inside Google Sheets.
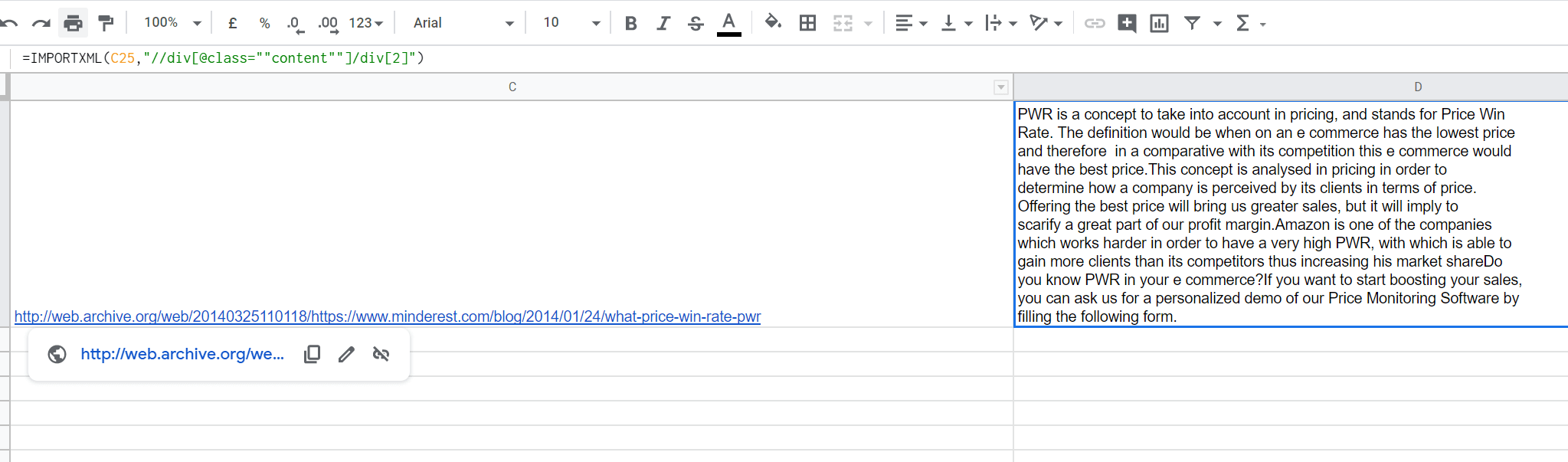
For the website we used as an example since the beginning, we can imagine that we want to extract the content of some blog posts that have not been migrated. By investigating a little bit, we would have realized that the main content is included in the second <div> inside a div with the “content” CSS class.
With this information, we extract the content directly in Sheets, using the IMPORTXML() function, indicating:
- The URL we want to extract the content from, which is the snapshot URL in our case
- The Xpath of the content we want to retrieve
And voilà, we get the content directly in Sheets. Pretty straightforward, right?
Be aware that finding a generic Xpath to extract only the content we want (and not the author name, comments etc…) can sometimes be challenging, but you would anyway save a lot of time, so it is completely worth it spending a while finding the perfect Xpath 😉
Once the content is recovered, you can add it again to your client’s website. You can copy-paste it because it was their content in the first place !
If you are working with Python, just use the beautifulsoup library to achieve exactly the same.
Conclusion
As we saw, archive.org is a powerful tool that can be leveraged for several SEO-related task. Even if its UI is slow, we can use its API or built-in Google Sheets funtion to use it at scale and save time. A huge time-saver and sometimes the only option we have to see and undertsnad what happened in the past.