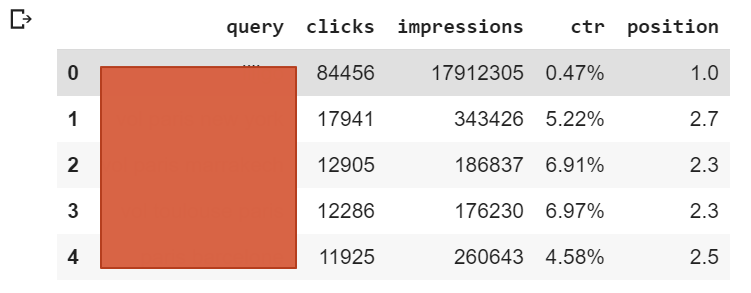
Cuando creas un contenido, a menudo intentas encontrar la(s) palabra(s) clave más buscada(s) para la(s) que necesitas optimizar tu contenido.
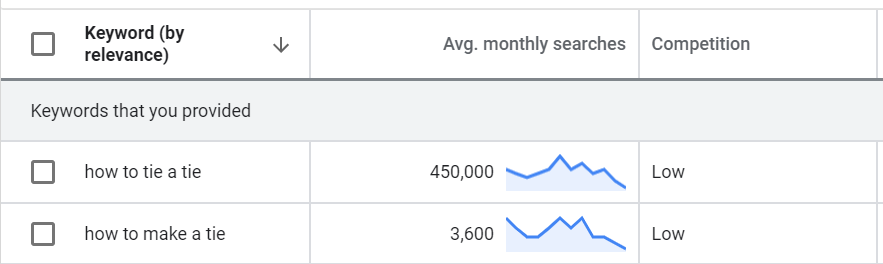
Imaginemos por un momento que diriges un blog en inglés sobre corbatas y creas un tutorial sobre cómo anudar una corbata correctamente. Si haces una investigación de palabras clave, la palabra clave principal es obvia, pero no puedes dejar de lado la segunda, porque puede producir tráfico adicional:
Tienes que intentar incluirlas en tu contenido para asegurarte de posicionarte correctamente en ambas palabras clave. Bastante sencillo, ¿verdad?
Sí, pero ¿cómo puedes optimizar contenidos en casos en los que tienes cientos o miles de palabras clave en las que quieres posicionarte? En el sector de los viajes, puedes buscar un vuelo utilizando muchísimas estructuras diferentes. Algunos ejemplos:
- Vuelo París Barcelona
- Vuelo barato París Barcelona
- Billete de avión París Barcelona
- Avión París Barcelona
- ….
Y a veces no hay una sola palabra clave con mucho más volumen de búsqueda que las demás, como el ejemplo de la corbata que acabo de mencionar.
En este artículo, te explicaré cómo puedes utilizar un análisis de N-gramas para hacer precisamente eso.
¿Qué es un análisis de N-gramas?
Primero, una definición rápida. Wikipedia indica que «un n-grama es una subsecuencia de “n” elementos de una secuencia dada». Básicamente nos dice cuántas veces se repite una palabra o una secuencia de “N” palabras en nuestra lista.
Se utiliza habitualmente en el campo del Procesamiento del Lenguaje Natural (NLP), pero no veremos algo tan avanzado y realizaremos un análisis básico de n-gramas.
¿Qué queremos conseguir?
Volvamos a nuestro ejemplo. Tenemos un conjunto de páginas que queremos optimizar en las palabras clave más importantes. Desgraciadamente son muchas y los volúmenes de búsqueda están distribuidos uniformemente. No hay manera de que podamos optimizar sólo dos de ellas por ejemplo.
En ese caso, lo que queremos saber es qué palabra o secuencia de palabras son las más comunes. De hecho, aunque la lista de palabras clave sea bastante larga, se puede detectar algunos patrones. Si nos ceñimos a nuestro ejemplo de los viajes, es probable que «barato» se repita bastante, y «vuelo» también. Pero, ¿debemos optimizar más en «vuelo» o «billete de avión»? No lo sabemos porque hay demasiada información y no podemos hacerlo usando la UI Google Search Console.
Queremos obtener una tabla como la siguiente, con los n-gramas a la izquierda. Soloasí podremos entender cuál es el peso de cada una de las estructuras.

Antes de empezar
En primer lugar, quería agradecer a Robin Lord y su presentación sobre Jupyter Notebook, incluyendo una parte del código que voy a mostrar en este artículo. Él es en realidad -sin saberlo- la persona que me hizo empezar a investigar lo que se podía hacer usando Python para el SEO.
Este artículo incluirá un poco de código, pero obviamente se puede hacer lo mismo en Excel. Como siempre lo menciono, es una cuestión de preferencia, pero lo que realmente importa es el resultado.
Descargue los datos de sus palabras clave
Tienes que descargar los datos de tus palabras clave utilizando la UI de Google Search Console o la API. Yo prefiero usar esta última porque la UI sólo te permitirá descargar hasta 1.000 palabras clave, que no es mucho.
Para utilizar la API, hay varias opciones:
- Construir la conexión usando la documentación oficial disponible aquí
- Utilizar esta librería si estás usando Python
- Utilizar esta extensión para usar la API directamente en Google Sheets. Ten en cuenta que puedes llegar a esperar un momento si quieres recuperar más de 5.000 filas.
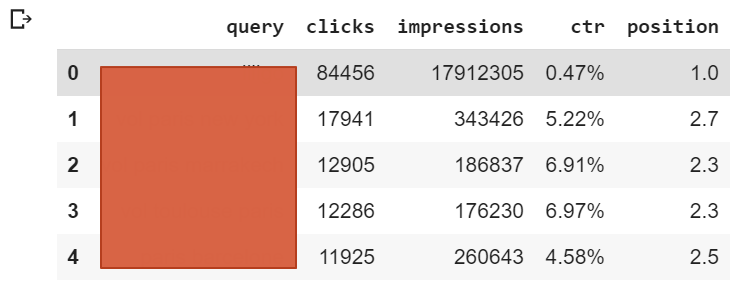
Necesitas recuperar tus palabras clave para un tipo de página específico. En nuestro ejemplo, queremos obtener los n-gramas de las páginas que pertenecen a la categoría «Rutas de vuelo», que son páginas para un viaje entre dos ciudades.
Independientemente de la opción que elijas, debería obtener una tabla con la siguiente estructura:
Cargar tus datos en Pandas
Si aún no lo has hecho, carga tus datos en un DataFrame de Pandas ejecutando el siguiente código:
import pandas as pd
df = pd.read_csv(‘path/to/your/file.csv’)Realizar el análisis de n-gramas
El código original es bastante largo, por lo que lo dividiré en pequeños segmentos y explicaré lo que hace paso a paso. En primer lugar, importamos nuestras bibliotecas y creamos una lista, incluyendo todas las palabras clave del paso anterior.
import collections
import nltk
import numpy as np
list_of_keywords = report['query'].tolist()A continuación, dividimos estas palabras clave en palabras utilizando los caracteres de espacio como delimitador. Por ejemplo, transformaremos «vuelo a París» en [«vuelo», «a», «París»].
list_of_words_in_keywords = [x.split(" ") for x in list_of_keywords]Después, creamos una variable que nos permitirá almacenar el número de veces que aparece un grupo de palabras.
counts = collections.Counter()Actualizamos esta variable para comprobar el número de veces que aparece cada palabra y par de palabras. Por lo general, añado sólo 1-gramas y 2-gramas, pero puedes añadir más n-gramas si lo deseas. Realmente depende de tu sector, pero limitarse a los 2-gramas es una buena práctica.
for phrase in list_of_words_in_keywords:
counts.update(nltk.ngrams(phrase, 1))
counts.update(nltk.ngrams(phrase, 2))Ahora, extraemos las 400 palabras o pares de palabras más comunes (en función del número de apariciones) y creamos un DataFrame de Pandas con ellas.
top_400=counts.most_common(400)
x = pd.DataFrame(top_200, columns=['query','count'])Creamos y aplicamos dos funciones para recuperar el volumen total de nuestros n-gramas y eliminamos los caracteres inútiles.
#Retrieve volume for each n-grams
def GetVolume(query):
df = report[report['query'].str.contains(query)]
return df['impressions'].sum()
#Remove useless characters
def RemoveUselessChar(x):
output=''
for element in x:
if "'" == element:
continue
elif '('==element:
continue
elif ')' == element:
continue
else:
output+=element
return output
#Apply all functions created before
x['query'] = x['query'].apply(RemoveUselessChar)
x['query'] = x['query'].str.replace(',','')
x['Volume'] = x['query'].apply(GetVolume)
x['type'] = x['query'].apply(ChangeCityKeyword)
Si llegas hasta aquí, deberías tener el resultado que queríamos. Cuando leas la tabla, debes entender que estás viendo una tabla que te dice qué palabras clave o par de palabras clave tienen más volumen de búsqueda que otras. Una parte de esta tabla podría ser:
| query | count | volume |
| vuelo | 50 | 167000 |
| vuelo barato | 676 | 30000 |
| billete avión | 300 | 97000 |
En español, la primera fila significa que hay 50 consultas que incluyen la palabra «flight» y que suponen 167.000 impresiones en total, según nuestros datos de GSC.
¿Qué puedo hacer con esa información?
Con tus n-gramas, podrás definir un conjunto de palabras clave para las que debes optimizar tu contenido. No puedes optimizar tu contenido sobre palabras clave individuales como el ejemplo que vimos al principio, pero puedes optimizar en bloque incluyendo las palabras clave más comunes o más buscadas.
La elección entre utilizar «billete de avión» o «vuelo» en tu <title>, donde tienes un espacio disponible muy limitado, dependerá del número que obtengas en tu tabla final cuando ejecutes el análisis de n-gramas.
Soy completamente consciente de que «billete de avión barato París Barcelona» y «vuelo barato París Barcelona» se refieren exactamente a lo mismo, pero Google no clasifica los sitios web en el mismo orden, de ahí, que sea importante decidir en qué términos centrarse al ejecutar este análisis de n-gramas. Sobre todo si trabajas en un sector en el que tienes varios miles de páginas que utilizan la misma plantilla en tu CMS.
Espero que te haya gustado el artículo. Si tienes alguna observación, no dudes en dejar un comentario 🙂