When you create a content, you often try to find the most searched keyword(s) you need to optimize your content for.
Let’s imagine a second that your run a blog around ties and you create a tutorial on how to tie a tie correctly. If you do a keyword research, the main keyword is obvious but you can’t leave out the second, because it can yield additional traffic:
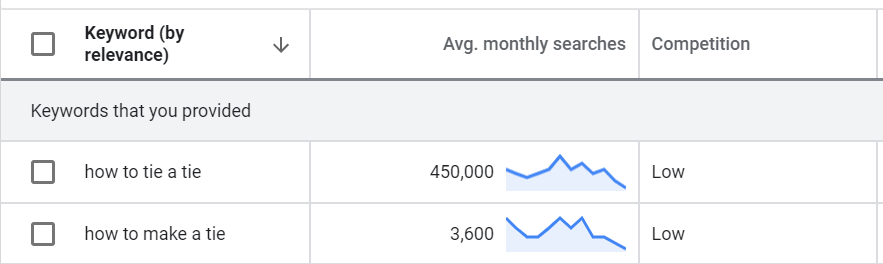
You have to try to include it in your content to be sure to be ranked correctly on both keywords. Pretty simple, right?
Yeah, but how can you handle content optimization in cases where you have hundreds or thousand of keywords you want to rank on? In the travel industry, you can look for a flight using a bunch of modifiers. Some examples:
- Flight Paris Barcelona
- Cheap flight Paris Barcelona
- Flight ticket Paris Barcelona
- Plane Paris Barcelona
- ….
And sometimes there is not a single keyword with way more search volume than the others, like the tie example I’ve just explained.
In this article, I will explain how you can use a N-gram analysis to do just that.
What is a n-gram analysis?
A quick definition first. Wikipedia indicates that “an n-gram is a contiguous sequence of n items from a given sample of text or speech.” It basically tells us how many times a word or a sequence of N words are repeated in our list.
It is commonly used in the Natural Language Processing (NLP) field, but we won’t go that far and we will perform a basic n-gram analysis.
What do we want to achieve?
Let’s go back to our example. We have a set of pages we want to optimize on most important keywords, unfortunately there are a lot of them and search volumes are evenly distributed. There is no way we can just optimize on just two of them.
In that case, what we want to know is which word or sequence of words are the most common. Indeed, even if the keyword list is quite long, some pattern can be spotted. If we stick to our travel example, “cheap” is likely to be repeated quite a lot, “flight” as well. But should we optimize more on “flight ticket” or “plane ticket”? We don’t know because there is too much information to digest and we can’t do it using Google Search Console UI.
We want to get a table like the following one, with n-grams on the left. We will then be able to understand which keywords we should optimize for.

Before we start
First of all, I wanted to give a shout to Robin Lord and his awesome presentation on Jupyter Notebook, including a part of the code I will be showcasing in this article. This is not the first version of this presentation and he is actually – without even knowing it – the person who made me start to look into what could be done using Python for SEO.
This article will include a bit of code but you can obviously do the same in Excel. As I always remind, it is a matter of preference, but what really matters is the outcome.
Download your keyword data
You need to download your keywords data using the Google Search Console UI or the API. I’d rather use the latter because the UI will only allow you to download up to 1.000 keywords, which is not a lot.
To use the API, several options:
- Build the connection using the official documentation available here
- Use this library if you are using Python
- Use this extension to use the API directly in Google Sheets. Please note that you may have to wait a while if you want to retrieve more than 5.000 rows.
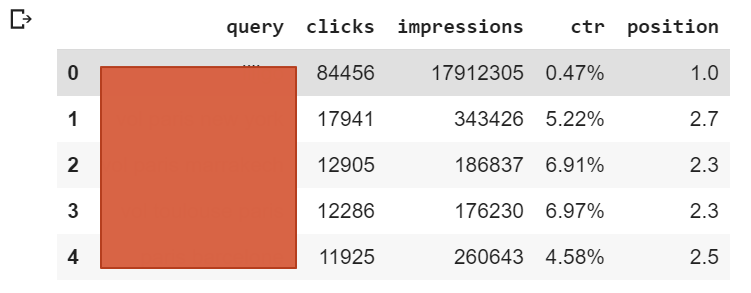
You need to retrieve your keywords for a specific page type. In our example, we want to get the n-grams for pages belonging to the “Flight Route” category, which are pages targeting queries for a travel between two cities.
No matter what option you decide to go with, you should end up with a table with the following structure:
Load your data in Pandas
If it has not been done already, load your data into a Pandas DataFrame by running the following code:
import pandas as pd
df = pd.read_csv(‘path/to/your/file.csv’)
Perform the n-gram analysis
The original code is quite long, therefore I will break it into small pieces and explain what it does, step by step. First, we import our libraries and create a list, including all the keywords in the previous step.
import collections
import nltk
import numpy as np
list_of_keywords = report['query'].tolist()
We then split these keywords into words using the space characters as the delimiter. We will transform “flight to Paris” into [“flight”,”to”,”Paris”] for instance.
list_of_words_in_keywords = [x.split(" ") for x in list_of_keywords]
Next, we create a variable that will allow us to store the number of times a group of words appear.
counts = collections.Counter()
We update this variable to check the number of times each single word and pair of words appear. I usually add only 1-gram and 2-grams but you can add more n-grams if you want. It really depends on your industry here, but limiting ourselves to 2-grams is a good practice.
for phrase in list_of_words_in_keywords:
counts.update(nltk.ngrams(phrase, 1))
counts.update(nltk.ngrams(phrase, 2))
We then extract the top 400 most common word or pair of words (based on the number of occurrences) and we create a Pandas DataFrame with them.
top_400=counts.most_common(400)
x = pd.DataFrame(top_200, columns=['query','count'])
We then create and apply two functions to retrieve the total volume for our n-grams and remove useless characters.
#Retrieve volume for each n-grams
def GetVolume(query):
df = report[report['query'].str.contains(query)]
return df['impressions'].sum()
#Remove useless characters
def RemoveUselessChar(x):
output=''
for element in x:
if "'" == element:
continue
elif '('==element:
continue
elif ')' == element:
continue
else:
output+=element
return output
#Apply all functions created before
x['query'] = x['query'].apply(RemoveUselessChar)
x['query'] = x['query'].str.replace(',','')
x['Volume'] = x['query'].apply(GetVolume)
x['type'] = x['query'].apply(ChangeCityKeyword)
At this stage, you should have the expected output we wanted. When you read the table, you need to understand that you are looking at a table telling who which keywords or pair of keywords have more search volume than others. A part of this table could be:
| query | count | volume |
|---|---|---|
| flight | 50 | 167000 |
| cheap flight | 676 | 30000 |
| plane ticket | 300 | 97000 |
In English, the first row means that there are 50 queries including the word “flight” and they account for 167.000 impressions in total, based on our GSC data.
What can I do with that information?
With your n-grams, you will be able to define a set of keywords you must optimize your content for. You can’t optimize your content on individual keywords like the example we saw at the beginning, but you can optimize in bulk by including most common or most searches keywords.
But whether to choose between using “flight ticket” or “plane ticket” in your title tag, where you have very limited space available, will depend on the number you get in your final table when you run the n-gram analysis.
I am completely aware that “cheap flight ticket Paris Barcelona” and “cheap plane ticket Paris Barcelona” refers to the exact same thing, but Google doesn’t rank websites in the same order, hence it is important to decide which terms to focus on at scale by running this n-gram analysis. Especially if you work in an industry where you have several thousands of pages using the same template in your CMS.
I hope you liked the article. If you have any remark, don’t hesitate to leave a comment :)Share:TwitterFacebookLinkedIn