Si llevas tiempo trabajando en SEO, seguramente estarás familiarizado con la migración de webs. Esto puede venir ocasionalmente con algunas complicaciones inesperadas y que pueden llegar a ser graciosas, pero siempre formarán parte de lo que hacemos para vivir.
Si se llega a manejar mal, una migración de una página web puede llegar a tener unos efectos tremendos en la visibilidad online y en el tráfico. Obviamente queremos evitar esto a toda costa porque es una situación que no queremos vivir. Además, una migración mal hecha puede ser una de las principales razones para que un dueño de un negocio comience a tomar el SEO en serio. Cuando estaba trabajando en una agencia, algunos de los clientes empezaron a trabajar con nosotros, después de haber tenido una experiencia horrenda.
En esta situación, la prioridad número uno cuando abordamos a nuestro cliente, es entender porque la migración está teniendo un impacto en la generación de tráfico y cómo solucionarla rápidamente. En ocasiones, las redirecciones están mal implementadas y necesitaremos empezar por revisarlas. Esto puede tomar mucho tiempo, incluso días dependiendo del tamaño del proyecto. Esta tarea normalmente se desarrolla por los miembros del equipo júnior (Yo fui uno de esos) cuyo único propósito durante estos días es rellenar un archivo de Excel.
Existen casos en los que este es el único caso posible porque no se puede encontrar ningún patrón para acelerar el trabajo. Esto está bien, pero en algunos momentos existen formas de solucionar los problemas de forma más eficiente.
Hoy te diré dos formas que son rápidas y eficientes en cuanto a costes, que podrán ahorrar muchos días de trabajo manual para tu equipo o para ti mismo.
Contexto
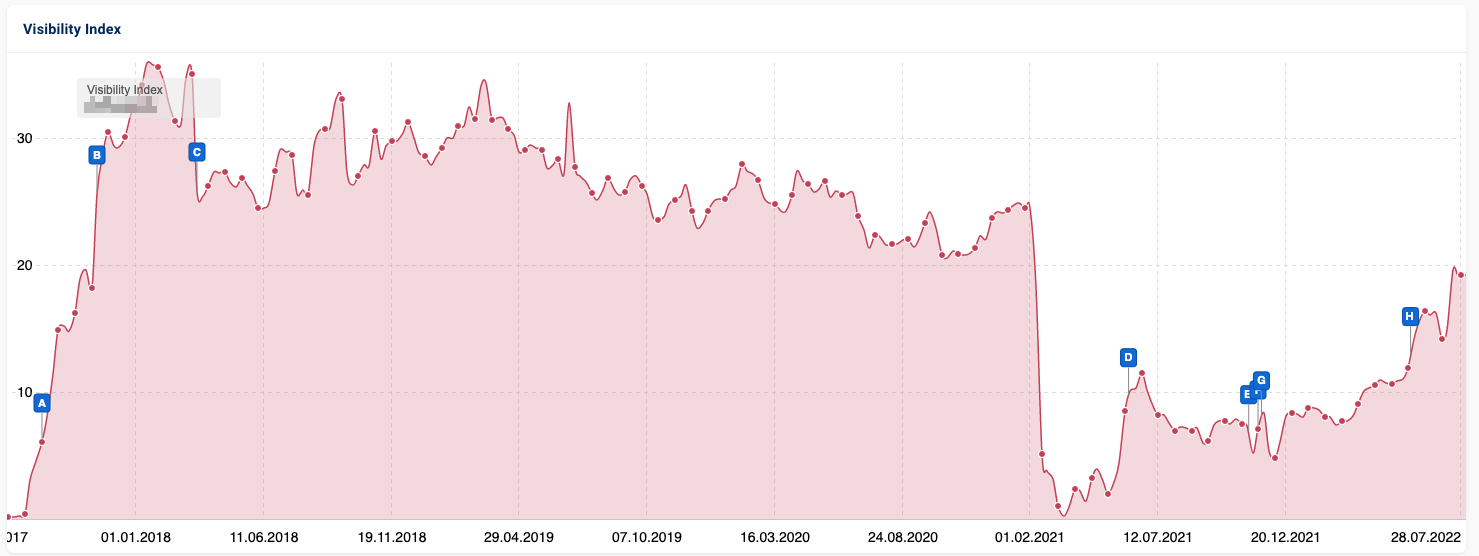
Para que proveerte un contexto real sobre el artículo que estoy escribiendo, utilizaremos una migración que ocurrió algunos meses atrás para una compañía de trenes francesa. Ellos decidieron migrar la web de https://oui.sncf/ a https://www.sncf-connect.com/.
La migración actualmente ha sido correcta desde una perspectiva del SEO, pero asumiremos que esto no fue así y la compañía vino a nosotros para intentar solucionar el problema. Esta web literalmente tenía miles de URLs, por lo que hacer un mapeo de las mismas de forma manual no es una opción.
Si observamos el historial de posiciones, nos daremos cuenta de que la ruta (la URL que se había eliminado del nombre de dominio) en realidad es la misma, por lo que en este caso se puede solucionar con una simple regla de redirección. Pero, asumamos -nuevamente, lo sé- que este no ha sido el caso, y tendremos que encontrar un equivalente a escala.
Opción 1: utilizar la proximidad semántica
Una migración web muchas veces viene con cambios de URL (que es el motivo por lo que tendrás que redirigir), pero frecuentemente se conserva una estructura similar. Normalmente, se añadirán algunas palabras, se removerán algunos números, pero aquí encontraremos un terreno común.
Con esta opción se aprovechará esto y podremjos tratar de encontrar el equivalente más cercano entre las estructuras antiguas y nuevas, mirando únicamente la URL. ¿Por qué no miramos el contenido?
- El contenido antiguo puede que no esté disponible.
- Rastrear un sitio web puede llevar mucho tiempo, y si omitimos este paso, podremos ayudar a nuestro cliente más rápido.
Entonces, ¿Cómo diablos vamos a lograrlo?
Coincidencia aproximada
Si no sabes lo que es la coincidencia aproximada, puedes leer este increíble texto de Lazarina Stoy, quién podrá explicarte todo.
Como un resumen:
- La coincidencia aproximada nos permitirá hacer coincidir cadenas similares. Esta es la técnica que utiliza Google para corregir los errores de escritura, por ejemplo:
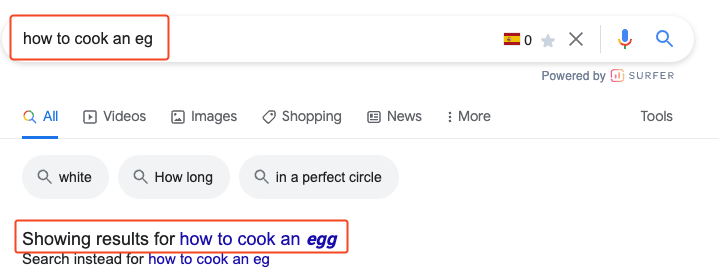
- Existen diferentes algoritmos disponibles, pero en nuestro caso, hemos utilizado el Levenshtein distance (busca coincidencias en palabras basadas en el número de ediciones necesarias para obtener una palabra a partir de otra) o TF-IDF que analizará que tanto se repite un cierto número de cadenas.
Algunas veces yo utilizo directamente Polyfuzz (una biblioteca de Python) cuando necesito utilizar las coincidencias aproximadas porque es más fácil de hacerlo. No te preocupes, no necesitarás ni Python o esta librería, y yo te explicaré todo e incluso te daré una plantilla.
Nuestra lógica
La lógica que vamos a codificar será bastante simple:
- Primero recuperaremos las dos listas de URL que queremos hacer coincidir (La antigua y la nueva).
- Ejecutaremos la coincidencia aproximada entre ellas para definir nuestras redirecciones.
- Compararemos el resultado de nuestra aproximación con las redirecciones actuales que SNCF ha puesto para calcular el porcentaje de éxito.
Trataremos de hacer coincidir alrededor de 3,000 URLs antiguas con una lista potencial de alrededor de 30,000. He utilizado intencionalmente un número más pequeño de URLs porque la segunda opción (que veremos en la siguiente sección) no es gratis, y no queremos gastar una gran cantidad de dinero en esta explicación.
El código
Puedes encontrar el código final y el resultado aquí. Incluso si no entiendes Python, verás lo fácil que resultará hacer esto.
Primero, las librerías que necesitamos para el script son: pandas y polyfuzz.
#load libraries
import pandas as pd
!pip install polyfuzz
from polyfuzz import PolyFuzzCargaremos nuestra lista de URLs (que debe estar guardada en un archivo de Excel) en pandas DataFrames (que es el equivalente de una tabla en Python):
#load urls lists
old = pd.read_excel('/content/drive/MyDrive/Website/Content/data_for_posts/redirects_at_scale.xlsx', sheet_name='old')
new = pd.read_excel('/content/drive/MyDrive/Website/Content/data_for_posts/redirects_at_scale.xlsx', sheet_name='new')Continuaremos por convertir nuestros DataFrames de pandas a listas regulares de Python (de lo contrario polyfuzz no funcionará) e iniciaremos las coincidencias aproximadas.
#convert to Python list (required by Polyfuzz)
old = old['URL'].tolist()
new = new['URL'].tolist()
#launch fuzzy matching
model = PolyFuzz("TF-IDF")
model.match(old, new)
#load results
result = model.get_matches()El resultado: nuestro mapeo de redireccionamiento. El resultado es casi perfecto (solo un 1.3% de error en nuestras casi 3,000 URLs) pero debemos tener en cuenta que estamos en una situación ideal aquí, donde l estructura antigua y la nueva son muy similares.
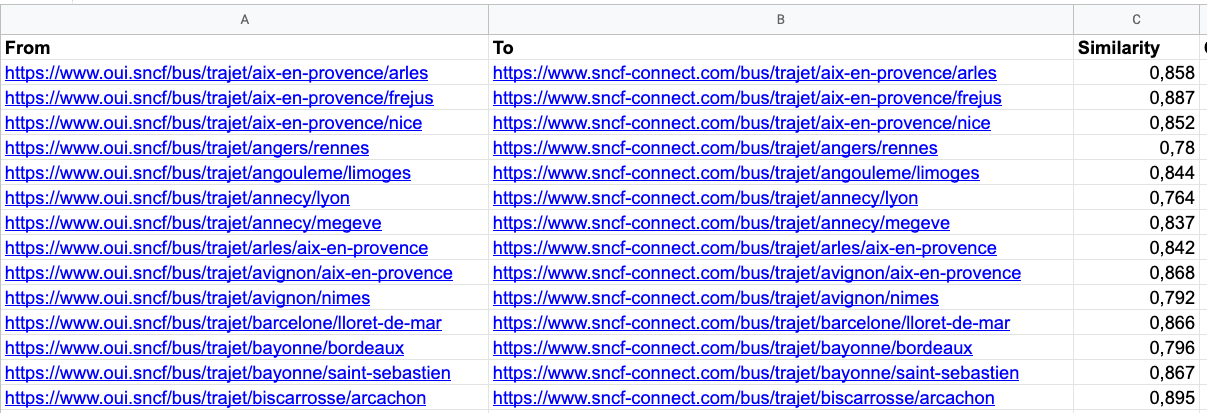
Pero aún así, esto nos podrá ahorrar mucho tiempo y solo necesitará una revisión manual antes de su implementación. Podrás generarlo en menos de 2 minutos.
Opción 2: ¡Google!, ¡Has el trabajo por mí!
La primera opción es mi favorita, poero este resultado dependerá en gran medida de que tan cercanas son las estructuras de las URLs. Es probable, pero no siempre será el mismo caso.
La segunda opción será mucho más robusta, pero solo funcionará si el nuevo contenido está indexado por Google, lo que significará que serás contactado solo unos días después de que la migración tome lugar (y esto podría ser muy tarde). Tampoco será una opción gratis, pero, tampoco será demasiado costosa.
Nuestra lógica
Nuevamente, la lógica será simple:
- Primero utilizaremos datos propios o de terceros, para extraer la palabra clave que estaba generando la mayor cantidad de tráfico por URL.
- Después, utilizaremos el site:operator, para tener los resultados más relevantes de acuerdo a Google para esta búsqueda.
Por ejemplo, https://www.theguardian.com/football/world-cup-2022 es la URL más relevante para la keyword “world cup” para The Guardian.
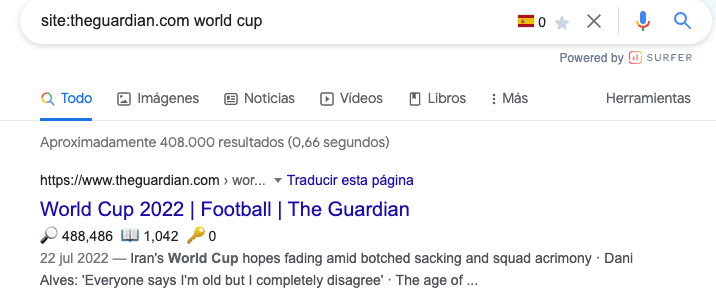
Para recuperar los datos a escala, tendremos que usar ValueSERP, que es una excelente API SERP.
El código
Podrás encontrar el código completo aquí. Esta es una opción más complicada que la anterior, pero voy a tratar de explicarla por completo.
La primera parte, como siempre, será cargar las librerías para lo que necesitaremos nuestro script: pandas, requests y json. También añadiremos una variable incluyendo nuestra API Key de ValueSERP. Esta la podremos encontrar en la parte superior de nuestro panel de control.
#load libraries
import pandas as pd
import requests
import json
#valueserp key
api_key = ‘’Continuaremos por cargar los datos de Semrush de nuestro antiguo sitio web. En mi ejemplo, he utilizado datos de terceros, pero si puedes, te recomiendo encarecidamente usar los datos de GSC. La lógica será terminar con la palabra clave más importante (en términos de tráfico) por URL.
#load file containing keywords
kw = (
pd
.read_csv('/content/drive/MyDrive/Website/Content/data_for_posts/oui.sncf_keywords.csv')
#keep only best kw by traffic
.sort_values(by='Traffic', ascending=False)
.drop_duplicates('URL', keep='first')
#add column with keyword to use in Google
.assign(Keyword_Google = lambda df:'site:sncf-connect.com '+df.Keyword)
)
#remove useless columns
kw = kw[['Keyword','URL','Keyword_Google']]En este punto, tendremos una DataFrame que contiene la consulta de Google, que va a ser utilizada para encontrar la redirección por URL.
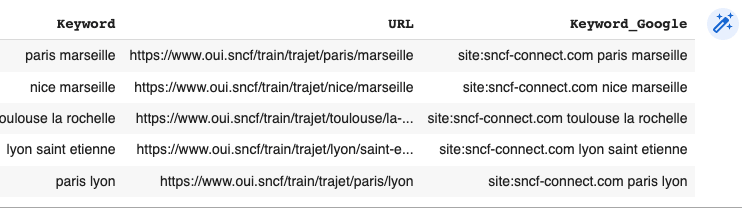
A continuación, enviaremos la información a ValueSERP. No te voy a explicar en profundidad esta parte, porque está basado en la documentación, pero si quieres usar mi código, necesitarás:
- Para crear más de un lote, porque no se pueden tener más de 1000 consultas por lote. Decidí limitar mi extracción a 1000 para reducir el coste asociado con este artículo.
- Actualizar la ubicación, el dominio de Google, dispositivo… basado en nuestro proyecto.
#list of queries to send to ValueSERP
#in this example, I'm just getting the data for 1000 keywords
kws = kw['Keyword_Google'].head(1000).tolist()
location = 'France'
google_domain = 'google.fr'
gl = 'fr'
hl = 'fr'
device = 'desktop'
num = 20
param_list = []
#create a list of parameters for each set
for i in range(0, len(kws)):
param_list.append({
'api_key': api_key,
'q': kws[i],
'location': location,
'google_domain': google_domain,
'gl':gl,
'hl':hl,
'device':device,
'num': str(int(num))
})
#create our batch
body = {
"name":'Demo_SNCF_Connect',
"enabled": True,
"schedule_type": "manual",
"priority": "normal",
"searches_type":"web"
}
#create batch
api_result = requests.post(f'https://api.valueserp.com/batches?api_key={api_key}', json=body)
api_response = api_result.json()
#get id
batch_id = api_response['batch']['id']
#send data to batch
for i in range(0, len(param_list)):
body = {"searches":[]}
for param in param_list:
body["searches"].append(param)
api_result = requests.put(f'https://api.valueserp.com/batches/{batch_id}?api_key={api_key}', json=body).json()Una vez ejecutado, tendrás un lote creado en ValueSERP y podrás (manualmente) ejecutar la extracción:
Esto normalmente es muy rápido (<1mn) y una vez que se haya terminado, podremos copiar el ID del lote para ejecutar el resto del código. Esto básicamente arrojará la información que provee ValueSERP, y aplicamos algunos filtros para encontrar los datos que necesitamos.
#required parameters
params = {
'api_key': api_key,
'page_size':1000
}
batch_id = ''
#get results for ou batches
results = pd.DataFrame()
#get batch info
api_result = requests.get(f'https://api.valueserp.com/batches/{batch_id}/results/1/csv', params=params)
for url_csv in api_result.json()['result']['download_links']['pages']:
results = results.append(pd.read_csv(url_csv), ignore_index=True)
#get results for ou batches
results = pd.DataFrame()
#get batch info
api_result = requests.get(f'https://api.valueserp.com/batches/3F3A94E1/results/1/csv', params=params)
for url_csv in api_result.json()['result']['download_links']['pages']:
results = results.append(pd.read_csv(url_csv), ignore_index=True)
#keep only top URL
results_filtered = results[results['result.organic_results.position']==1]
#remove unsucessful scrape
results_filtered = results_filtered[results_filtered['success']==True]
#keep only useful columns
results_filtered = results_filtered[['search.q','result.organic_results.link']]
#use more standard names
results_filtered.columns = ['Keyword_Google','Redirect_URL']
results_filtered.head()
Terminaremos con un DataFrame incluyendo nuestra consulta y el mejor resultado, de acuerdo con Google. Podremos en este punto combinar los datos con nuestra tabla inicial, como lo hicimos cuando utilizamos Polyfuzz.

El resultado es peor que con la primera opción (8.6% de error) pero aún así es un resultado satisfactorio. Simplemente imagínate el número de horas que habrás ahorrado.
Conclusión
Las redirecciones pueden consumir mucho tiempo, pero si se utiliza alguna de estas dos opciones podremos acelerar significativamente nuestro trabajo, y podremos darle a nuestros clientes un mayor valor agregado, en lugar de muchas horas de un trabajo manual de todo el grupo durante varios días. Y podrás gastar más tiempo en tareas que no se pueden automatizar.
Trabaja inteligentemente, no más duro. 😉