
Regular expressions – commonly referred to as RegEx – are a series of characters that are interpreted to identify patterns. They are supported by almost all programming languages and tools, such as Google Search Console or Screaming Frog, to name just a few. Sadly, RegEx can be intimidating and are seen as a tool that is powerful for data analysis but impossible to master for the majority.

Which I honestly believe because I’m yet to meet someone who would claim that. But you know what? It doesn’t matter. I use RegEx daily, and yet I master only the basics. Which is more than enough for most cases.
Why and when should I care about RegEx?
There are many skills that you can learn and apply in the search industry. Their usefulness depends on several factors, such as:
- Your seniority level: I wouldn’t advise learning RegEx if you don’t master the basics of SEO.
- The kind of SEO you are: RegEx are more useful when you deal with a lot of data. If you make a living by creating niche websites, it may not be as useful as if you’re responsible for the SEO strategy at Walmart.
Don’t learn it just because you’ve liked this post, learn it because it could help you during your daily tasks.
That being said, keep in mind that RegEx are supported by the vast majority of SEO tools such as Google Analytics, Google Search Console, Screaming Frog, Oncrawl and I could go on forever. You even have Google Sheets formulas (REGEXMATCH and REGEXEXTRACT) to use them directly in Excel.

One smart example to leverage RegEx inside Google Search Console to pull questions around your brand. And I’ve used this trick in the past and it’s awesome to improve your FAQ / Customer support section. Without RegEx, pulling these questions would take more time.
RegEx 101
As I already highlighted, in most cases, RegEx can actually be pretty simple. If you understand a few concepts, you’ll be able to use them with, maybe, a bit of Googling.
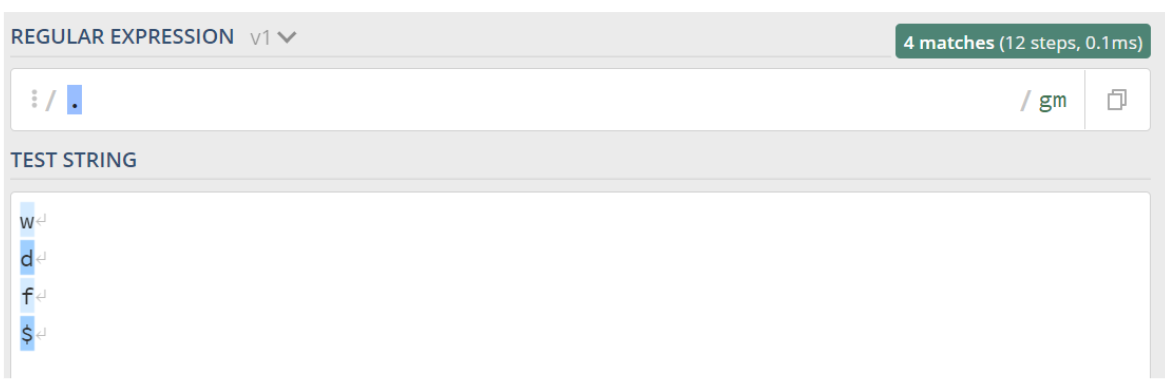
dot (.)
The dot is a wildcard that can match any character. It can be a letter, a number or a special character, it doesn’t matter. It’s not often used by itself, though: it usually comes with a quantifier that I’ll explain later in this article.
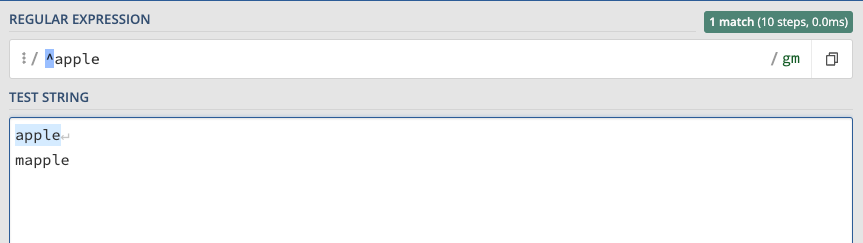
circumflex accent (^)
The circumflex accent indicates the beginning of a text we are trying to match. ^apple only matches apple in my example below because the other word starts with the letter m. In plain English, this character will allow identifying strings that start with a specific text.
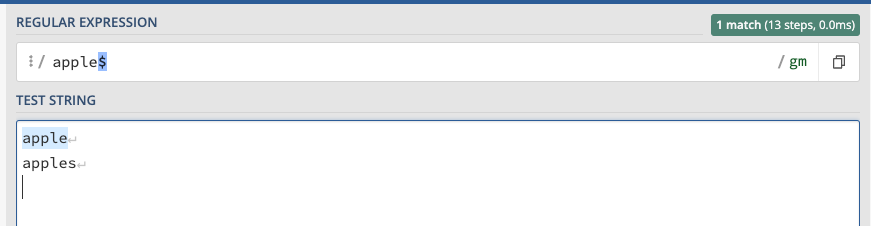
dollar sign ($)
The dollar sign does the opposite of the circumflex accent: it allows identifying a string that ends with a specific text,
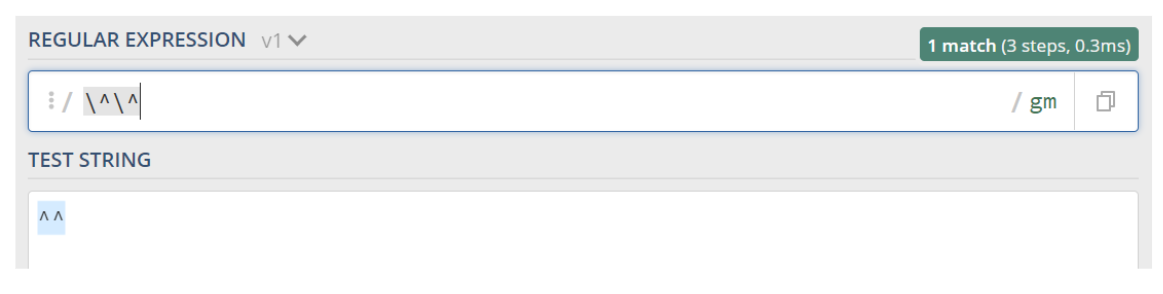
backslash (\)
As we are explaining, some characters have a special meaning when you are using them in a RegEx context. Now, what about matching these characters and not their meanings? How can we match a text including circumflex accents, for instance? You just have to use the backslash before them, whose purpose is to indicate that this character should be interpreted literally, and not with its meaning.
several options
Sometimes, you can have ore than one option to match a string. RegEx have several patterns to achieve just that:
- [abc] indicates that you can have the letter a, b or c. Any of these options is fine. Example:
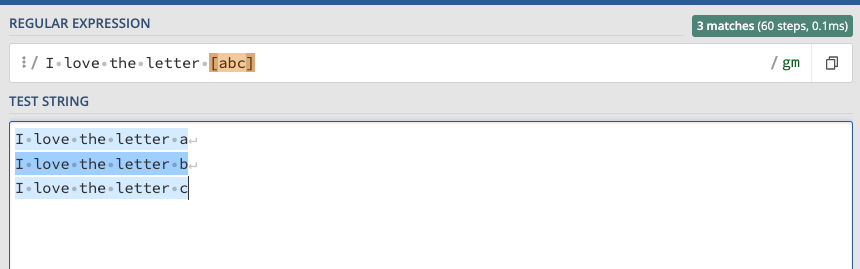
- [a-z] matches any lowercase letter from the Latin alphabet (if you speak spanish, ñ is not included).
- [A-Z] does the same, but for capital letters
- [a-zA-Z] matches any letter, whether it is lowercase or capital
- [0-9] matches any digit
It’s not that hard, is it? The only thing you’ll have to remember is how to type a bracket using your keyboard. Because it will be required quite often.
Quantifier
While the regular expressions we’ve seen in the previous sections will cover most of your cases, we still need to learn a key concept: the quantifier. These characters indicate how many times a specific string can be repeated.
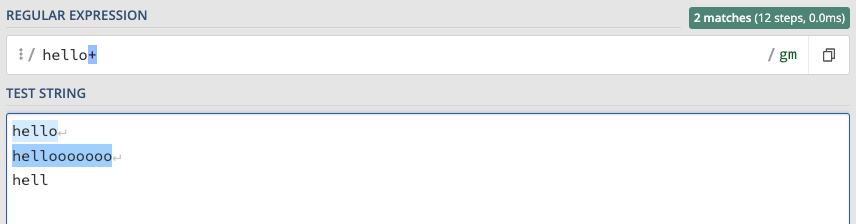
A quantifier is always applied to the character located before. In my example below, the plus sign (+), which mean 1 or more times, is applied to the letter o. Which is why it matches with the two first options, but not the third because it doesn’t include the letter o.
The main quantifiers are the following:
| Character | Meaning |
| * | 0 or more times |
| + | 1 or more times |
| ? | 0 or 1 time |
| {X} | X times |
| {X,Y} | Between X and Y times |
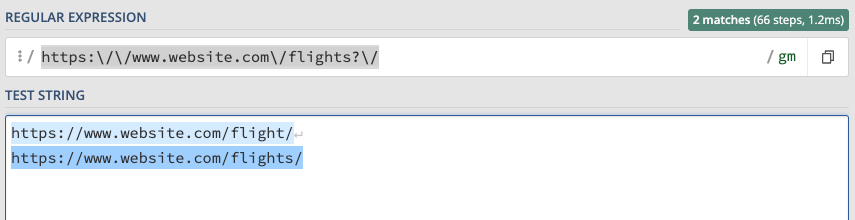
For instance, we can match two folders, /flight/ and /flights/, with a single RegEx by indicating that the letter s is optional.
Let’s practice: a simple example
Let’s apply some of the concepts we’ve seen so far. Let’s imagine that you are working for a website selling plane tickets. Your web architecture includes thousands of URLs built following this pattern:
- URL: https://www.example.com/flights-barcelona–paris_bar–par.html
- Explanation: https://www.example.com/flights-{origin}-{destination}_{airport_origin}-{airport_destination}.html
From the explanation, we need to transform the variable into valid RegEx:
- origin / destination: a word without space: [a-z]+
- airport: three underscore letters: [a-z]{3}
Which will become:
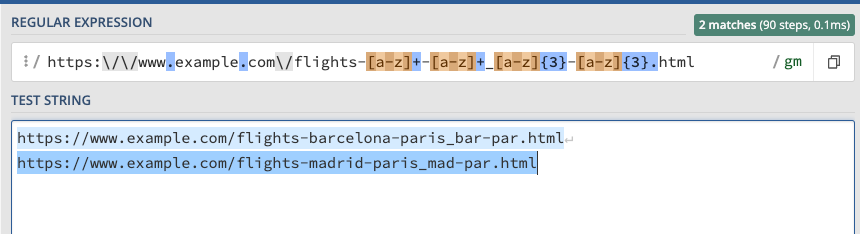
https://www.example.com/flights-[a-z]+–[a-z]+_[a-z]{3}–[a-z]{3}.html
That’s completely normal if it’s not (yet) easy to come up with custom RegEx quickly, but you’ll get there. As I highlighted, you may encounter specific cases where the RegEx I explained in this article are not enough, but you should be good for most cases.
Let’s practice with a more complex example
For this second example, let’s assume that we are working for Animalear, a Spanish E-commerce for pets. I’ve actually worked for this client when I started my professional career in Spain. It brings good memories back 😉
We know that this client has a problem with some of its product URL.
- Some are user-friendly such as https://animalear.com/perros/scalibor/collar-scalibor-antiparasitario
- Other aren’t such as https://animalear.com/perros/nutro/p-195619
You can obviously rank with both, but the former is better for several reasons. What we want to do is simple: check that we are not using the bad structure in our internal linking from key pages such as the homepage and categories.
We could obviously perform this check manually, but if we have more than 10 pages, we’ll spend a significant amount of time. Let’s see how we can use RegEx to help us here.
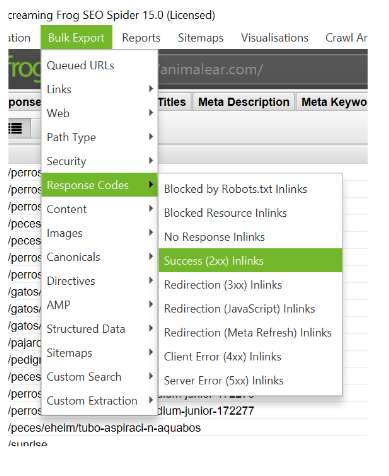
- Let’s crawl the full website using Screaming Frog or any similar crawler

- We then export the inlinks report
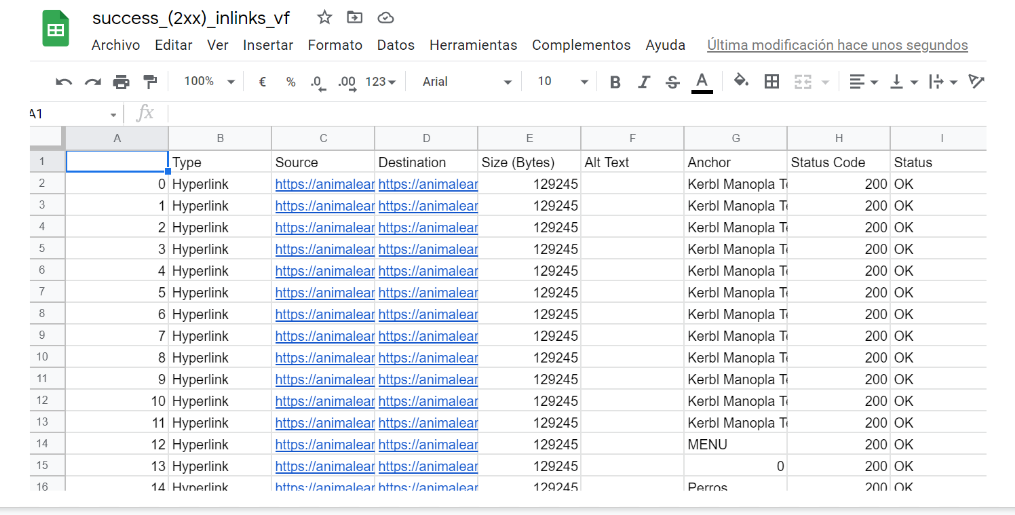
- We then open the file in Google Sheets. Please note that if the crawl is too big, you may not be able to open the file in Sheets.
- We continue with our process: we are looking for links FROM categories TO non-optimized URLs. Categories have two different structures: https://animalear.com/pajaros/c_juguetes-para-pajaros and https://animalear.com/gatos/s_accesorios-casetas. In plain English: domain + a folder + the letter c or s followed by an underscore and the rest of the URL. Which can be translated in REGEX; using the explanations given before, by https:\/\/animalear.com\/.*\/[cs]_.*
- Applying the same logic with product URLs (such as https://animalear.com/perros/nutro/p-195619), we define the RegEx https:\/\/animalear.com/.*/p-[0-9]+$. In English: domain + folders + the letter p + dash + some numbers
- Using the REGEXMATCH formula, we can filter our file to include only rows with the links we were looking for.
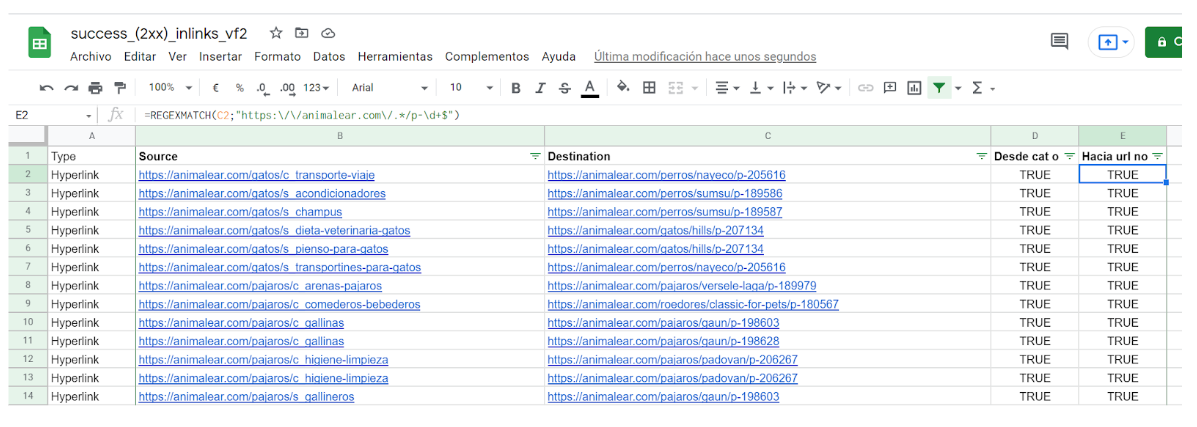
Quicker than doing the whole thing manually, right? And we didn’t create complex RegEx.
Conclusion
As I mentioned in my introduction, RegEx can be complex, but they often won’t be. By knowing your way around the basics, you’d be able to:
- Work smarter in Google Sheets
- Leverage Custom Search & Extraction in Screaming Frog or Oncrawl
- Categorize your sections in Data Studio
- And so much more
I strongly advise taking some time to learn the basics if you are dealing with a lot of data. You don’t have to know everything, and you will save so much time in the long term that it will be worth it.