Google was founded in 1998, and the web has evolved quite a lot since then. One of the main changes is the increase in websites that rely on JavaScript frameworks. You are very likely to have heard of them already, but they really started to appear in the mid-2010’s (source).
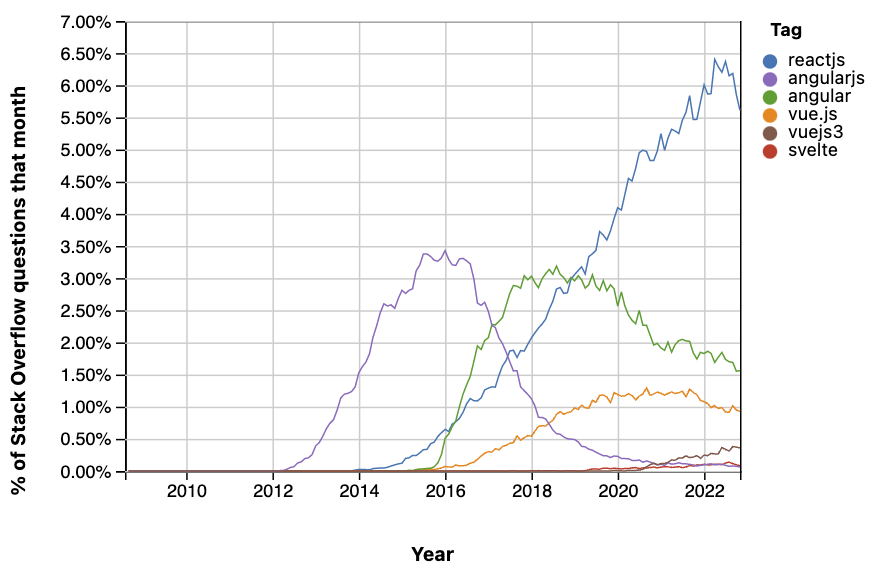
These frameworks are obviously great from a development standpoint, even though we can have our concerns about the framework lock-in when we look at the trend of some of them. Indeed, if a framework popularity is decreasing and if your company is using it, you’ll have to pay a premium to maintain it because available resources will be scarce.
Google evolved following this trend, and while it now widely supports JavaScript in its rendering process (see documentation), there are countless issues (such as content hydration) and horror stories that led to SEO disasters.
Now, this content is not about making sure your JS framework is SEO-ready. This content is about a common misunderstanding of how the Google cache can be used in this context.
The common error
By Google’s own definition, the cache can be defined as follows:
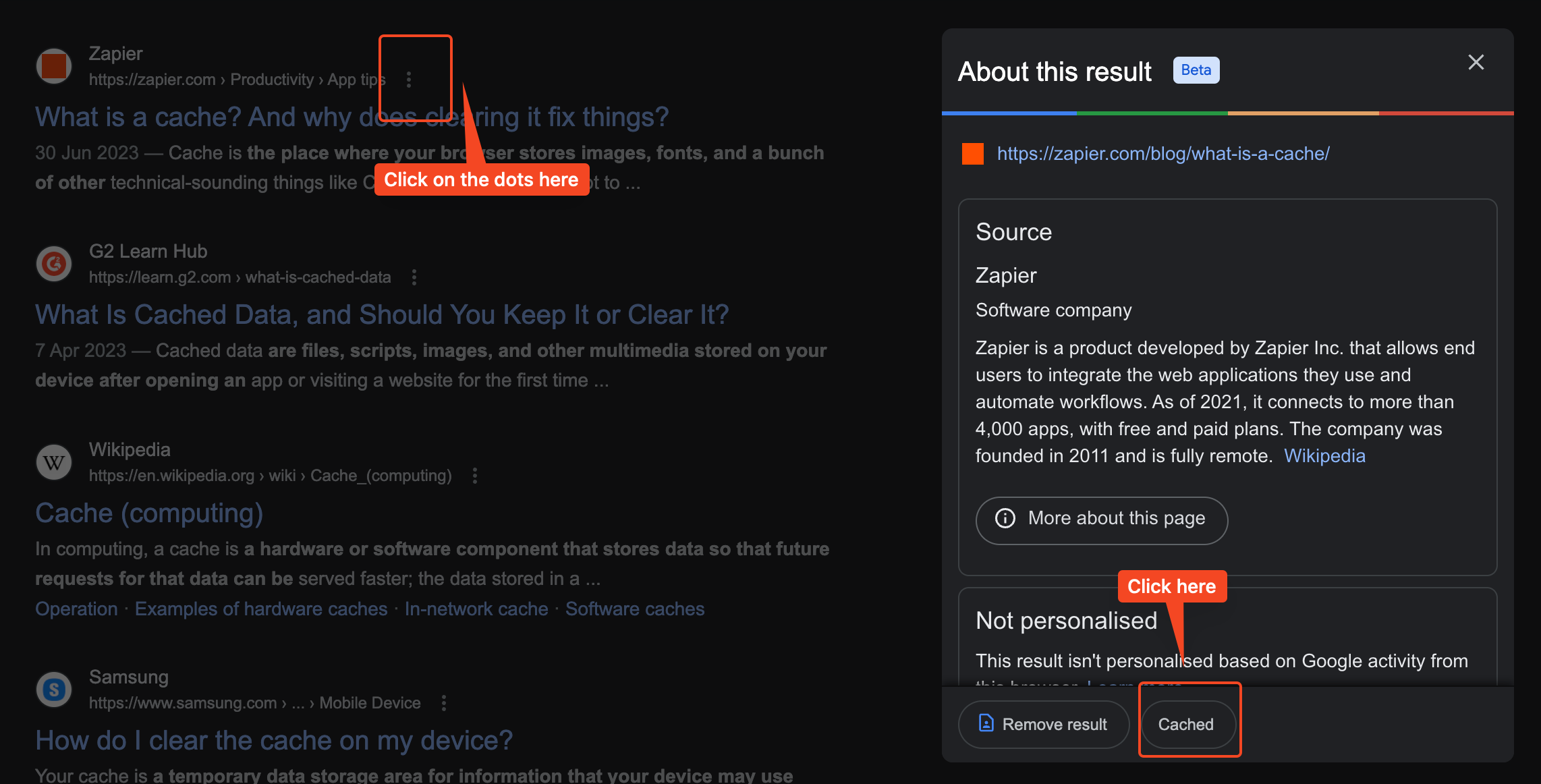
Google takes a snapshot of each web page as a backup in case the current page isn’t available. These pages then become part of Google’s cache. If you click a link that says “Cached,” you’ll see the version of the site that Google stored.
You can access the cached version of any webpage (not using the noarchive directive) easily from any Google SERP:
The cache would be a way of understanding how Google sees our website. This is one of the first you’d have to check if you know that a website relies on a JS framework, where a bad implementation could literally kill your SEO because Google cannot see your website.
Let’s use an example: Liligo is a travel website currently using Angular, one of the most-known JS frameworks. If I open the cache, I see what we don’t like to: a blank page.
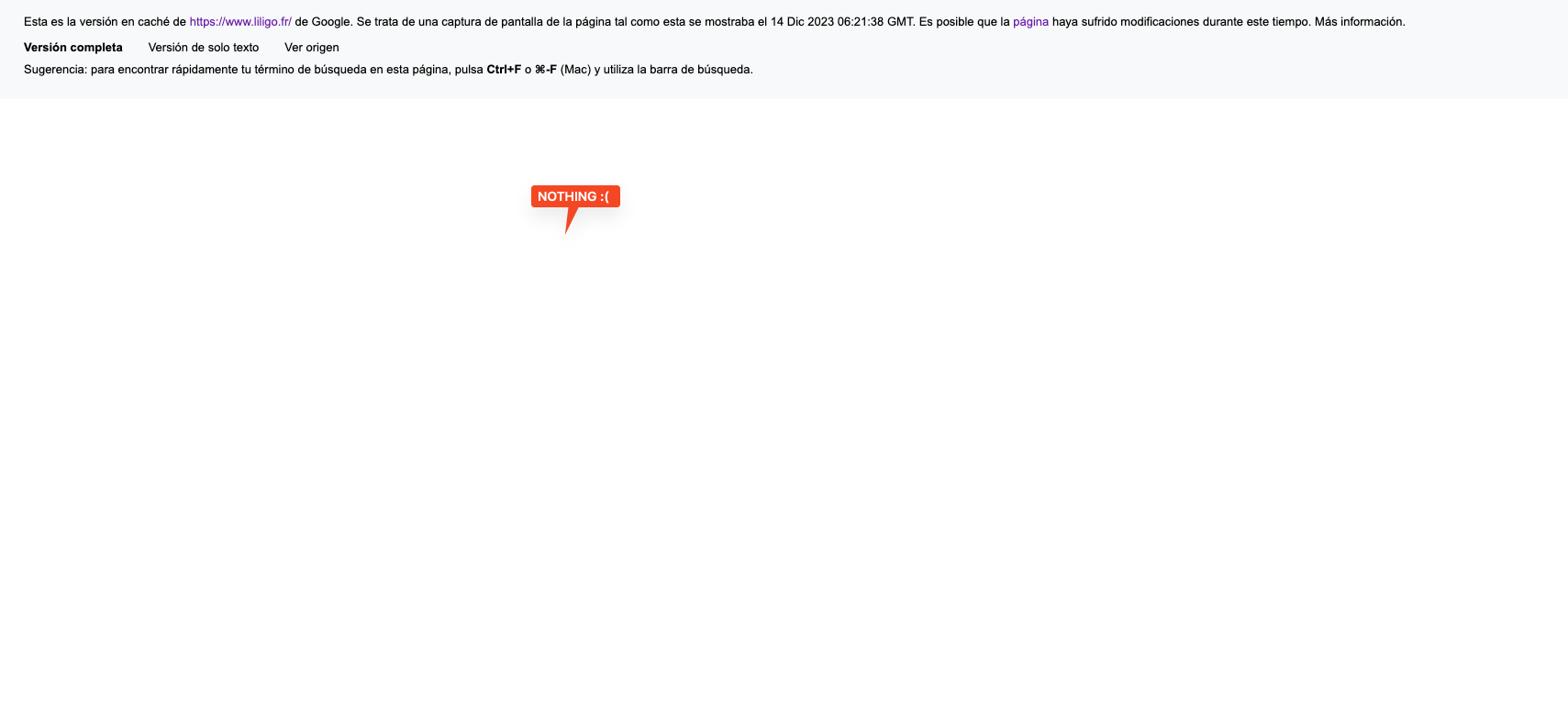
Based on that, we could tell our client that there is an issue with how they implemented everything, and it needs to be updated. Is it really the case, though?
How is the cache tricking you?
If I run the same analysis using GSC, I can clearly see that Google is not having any problem rendering the page. The content and the design are rendered perfectly. So, why am I seeing something different in the cache, and which one should I trust?
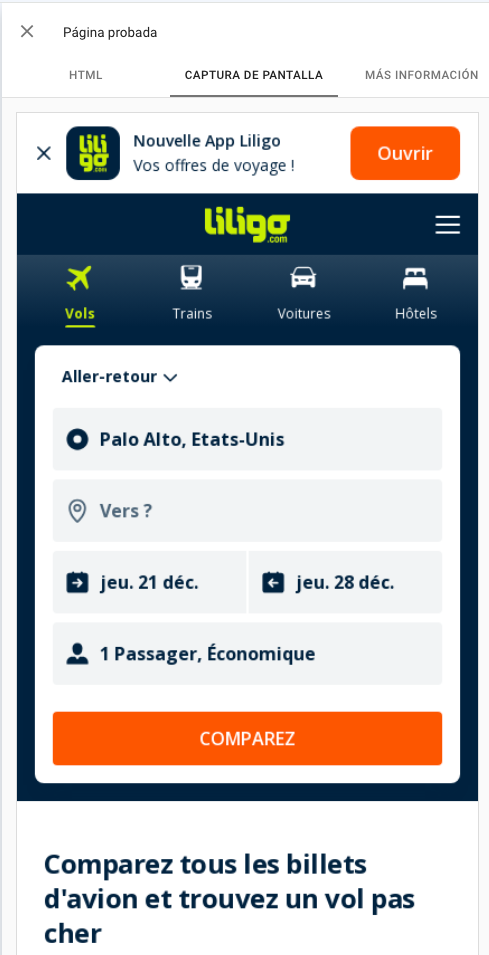
The reality: the cache is not an accurate representation of what Google sees and often cannot be trusted.
Indeed, the cache is the content seen by Google, loaded from the domain https://webcache.googleusercontent.com/ and interpreted by your browser. See the difference?
One of the most common situations where you’ll therefore see a difference between the cache and what Google really sees is when you have a strict CORS policy in place.
Cross-Origin Resource Sharing (CORS) is an HTTP-header based mechanism that allows a server to indicate any origins (domain, scheme, or port) other than its own from which a browser should permit loading resources.
In English: you can tell a server to prevent a resource (such as a JS file) from loading if the request doesn’t come from your domain. When you see the cache, the domain https://webcache.googleusercontent.com/ is trying to use some resources that are hosted in another domain. If it can’t, you’ll have a bunch of errors in the console, and it may explain why you’re seeing a blank page, especially if a part of the rendering process is based on JS & CSS files (which if often the case).
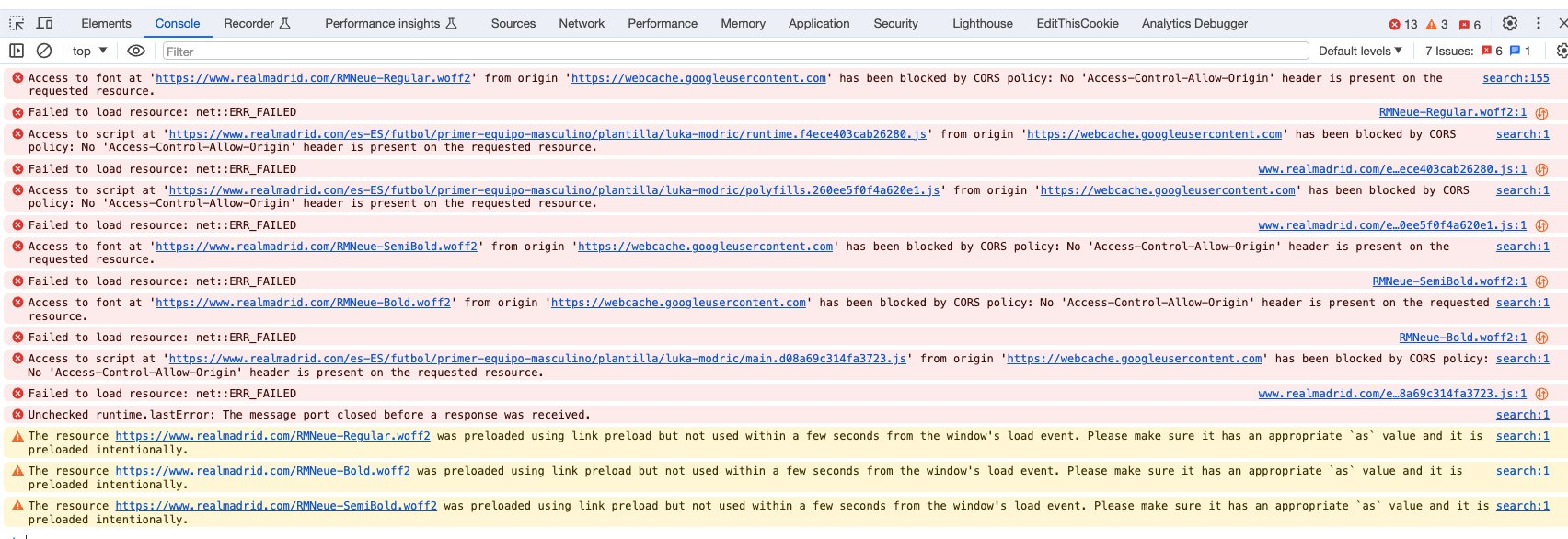
But that doesn’t mean that the page has a rendering issue.
This situation is quite confusing, and I’ve been tricked some years ago when I was working agency-side. We tried to solve a non-existing issue with a client. Sad to think about it now, but it’s part of the learning process, I guess.
Conclusion
The cache is a powerful tool, but don’t let it trick you into a false conclusion until you really understand how it works 🙂